ユーザビリティテストデータを4ステップで分析する
関連するデータを収集し、それを批判的に評価し、検証可能な説明を組み立てることで、自信を持って分析しよう。
定性的なユーザーテストの分析が複雑である理由
教科書では、定性的なユーザビリティテストのデータ分析は、ユーザビリティ上の問題を一覧化し、タスクの遂行状況を要約し、エラーを集計し、タスク所要時間を集計する、といった単純明快なプロセスとして提示されることが多い。しかし、こうした分析は常にそれほど容易とは限らない。これはとりわけ次のような場合に当てはまる:
- 通常とは異なる調査デザイン(例:1回のセッション内で各参加者に複数バージョンのプロトタイプを提示するなど)
- 気づきやすさ、理解度、ユーザーがどのように問題を解決するかといったトピックに関わる、複雑な調査課題
- すべての機能、コンテンツ、画面が揃っていない低忠実度のプロトタイプ
新しい商品詳細ページをデザインしていて、これをテストしたいとしよう。参加者には、プロトタイプ上で特定の商品を探し、自分に最適な商品を選ぶよう求めるとする。以下は、その調査課題の一部である。
- 商品比較機能に気づきやすいか。
- 商品に関するどの情報がユーザーにとって重要で、どの情報が重要ではないか。
- 商品概要の情報は理解されているか。
- 商品の仕組みは理解されているか。適切なメンタルモデルが形成されているか。
1つのタスクの遂行状況を調べるだけでは、こうした調査課題に答えるのは難しいかもしれない。これらの問いにうまく答えるには、次の作業が必要になる:
- 複数のデータ(セッション中の複数の時点における人々の行動や発言)を収集する
- そのデータを調査デザイン、募集の詳細(誰が調査に参加したか)、さらにはファシリテーション時の出来事(すなわち、リサーチャーの行動や発言)と照らし合わせて検討する
- これらすべての情報を三角測量(トライアンギュレーション)し、信頼できる答えを提供する
分析と統合
データから知見へ、そして提言へと進むには、分析と統合という2つの活動を組み合わせる必要がある。
分析とは、複雑な情報を分解して精査することを指す。これに対し、統合とは、情報を再構成し、新たに意味のある形、すなわち知見にまとめることを指す(なお、調査プロセスの段階として「分析」と言うとき、実際にはこの2つの活動の両方を指している)。
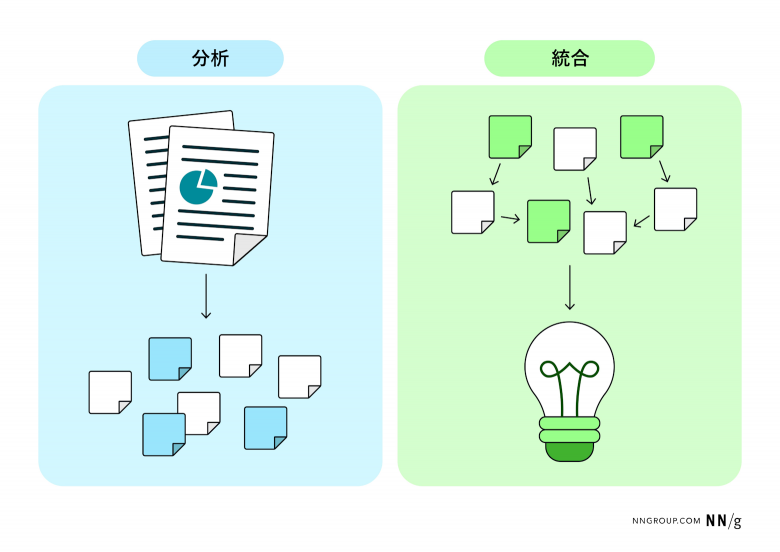
定性的データを分析する際、分析と統合は整然とした直線的な流れで進むわけではない。ときにはその2つの間を行き来しながら進めることもある。
ユーザビリティテストデータを分析する4ステップ
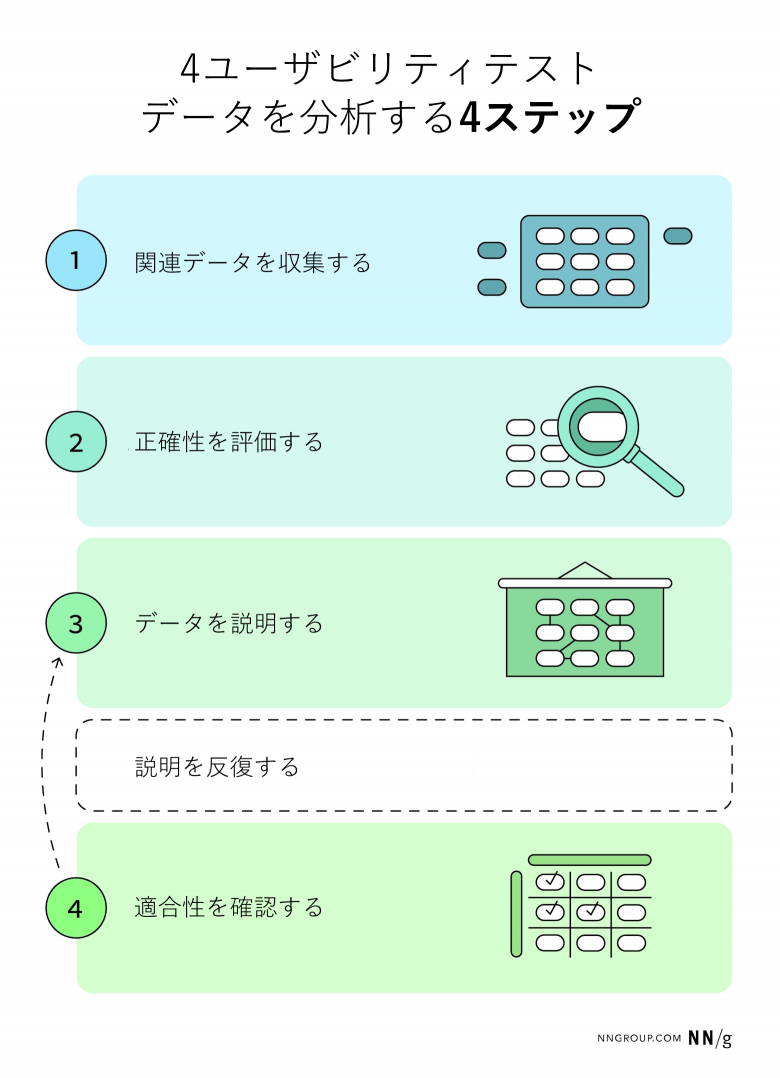
ユーザビリティテストデータからどのように知見に到達するか、そしてそこでの分析と統合のプロセスがどのようなものかを示すため、4つのステップからなるフレームワークを提案する。
- 関連データを収集する:各セッションから、調査課題に関連するデータポイント(観察記録と発言)を選び出す。このステップでは分析を行い、データセットをより扱いやすい形に絞り込む。
- 正確性を評価する:各データポイントを検討し、その関連性と正確性を評価する。ここでも、我々は依然として分析フェーズにある。
- データを説明する:データポイント(ステップ1)、評価(ステップ2)、我々の専門知を組み合わせて、調査課題への妥当な説明や回答を提示する。このステップでは統合を行う。
- 適合性を確認する:収集したデータに照らし、説明や調査課題への回答が適合しているかを確認する。その説明は収集したすべてのデータを説明しているか。そうでない場合は、(ステップ3に戻って)説明を見直す。ステップ4では再び分析が行われる。
このプロセスは直線的に見えるが、ステップ3と4はしばしば反復的である。実務では、データの小さなサブセット(記憶に残りやすい、あるいは目立つデータポイント)に基づいて初期の説明を組み立てがちだ。しかし、それらの説明をより広範なデータセットに照らして検証すると、当初の考えに反する不整合や、見落としていたパターンに気づくことがある。これが説明の精緻化を促す。ステップ3と4の間のこの行き来は何度も起こりうる。
ステップ1. 関連データを収集する
ユーザビリティテストでは大量のデータが生成される。「収集」段階では、我々は調査課題の回答に役立つ可能性のあるすべての関連するデータポイントや観察記録を収集することから始める。(これは果樹園でリンゴを摘むのに少し似ている。見込みのありそうなリンゴを選び取っているのである。)これを行うために、セッションのメモ、書き起こし、および利用可能であれば録画を精査する。そして関連する観察記録や発言は、メモするかコード化する。
たとえば、商品詳細ページの比較機能にユーザーが気づきやすいかどうかを理解しようとしている場合、関連するタスクを実行しているときの参加者の行動、その場での発言、そしてファシリテーターのフォローアップ質問への回答に関するデータポイントを収集するために、メモや録画を再確認するかもしれない。そのときに想定される問いには次のようなものがあるだろう:
- 参加者はその機能を使用したか、あるいは(たとえば、その機能にマウスカーソルを合わせたことでわかるように)気づいたか
- 参加者は思考発話しながら、あるいはファシリテーターのフォローアップ質問への回答の中で、比較機能や比較の必要性に言及したか
- 比較機能を使用しなかった場合、参加者はどのように比較タスクを実行したか
このステップは分析を伴う。なぜなら、ここではデータセット全体を分解し、その中から有用な項目の小さな集合を抽出していくからだ。
ステップ2. 正確性を評価する
ステップ2では、我々は依然として(統合ではなく)分析の段階にいる。「評価」のステップでは、各データポイントの関連性と重みづけの程度を判断するためにそれらを精査する。すべてのデータポイントが等しく扱われるわけではない。リンゴ摘みのたとえを続けるなら、これは収穫者が各リンゴに傷みや他の欠陥がないか検査するようなものだ。
たとえば、ある参加者が比較機能を気に入ったとコメントしたものの、実際には一度も使わなかった、という場合もあるかもしれない。あるいは、このコメントがファシリテーターの誘導尋問(例:「比較機能は気に入りましたか」)への回答だった可能性もある。こうした詳細を知ることで、そのデータポイントへの信頼の度合いは多少増減する。
ステップ3. データを説明する
ステップ3では、観察記録、評価、専門知識を組み合わせて、収集したデータに対して可能性の高い説明(仮説)を導き出すプロセスを開始する。
収集したデータによっては、複数の説明が成り立つこともある。たとえば、デザインした比較機能に参加者全員が気づかなかった場合、次のような説明が考えられるかもしれない。
- 考えられる説明1:その機能がユーザーが予想した場所に配置されていなかった。
- 考えられる説明2:その機能が見えにくかった、あるいは気づきにくかった。
- 考えられる説明3:その機能はそのタスクにおいて参加者にとって有用ではなかったため、彼らはそれを探さなかった
説明を考えるには、UXの知識と経験に加えて、ある程度の想像力を必要とする。たとえば、リサーチャーが過去に類似のデザインに関する調査を実施しているなら、人間の行動に関する豊富な記憶とデザインのベストプラクティスに関する知識が拠り所になりうる。
ステップ4. 適合性を確認する
ここでは、ユーザー行動に対する可能な説明を絞り込み、説明に対する確信を深めるため、既存のデータに照らして説明が適合するかどうかを検証する。収集したデータはその説明を裏づけるか。説明と食い違う、またはその正確性に疑問を生じさせるデータポイントはないか。このステップは、パズルのピースがぴたりとはまるかどうかを確かめるようなものだ。
たとえば、参加者が商品概要ページで比較機能を使わず、それはユーザーにその機能が必要なかったからだと我々が解釈した場合には、参加者は商品を比較するために別の有効な方法を用いていたと考えられる。しかし、参加者が比較に苦労していたり、比較のためにたくさんの商品概要ページを複数のタブで開いたり、利用可能な商品の比較が難しいと不満を述べていたのであれば、その説明を採用することはないだろう。データに照らすと不正確に思えるからである。
ここで起きているのは仮説検定の一形態だ。説明が予測を導く。したがって、データがその予測を裏づけない場合、説明を採用しないか、精緻化することになる。
定性調査はしばしば貴重な知見や答えを明らかにする一方で、さらなる調査を要する新たな疑問を同じくらい生み出すこともある! 分析の結果、データの背後にある理由がまだわからず、さらに調査が必要だと報告して締めくくってもかまわない。しかし、優れたアナリストの証は、データを多角的に検討し、複数の説明をデータに照らして検証し、今後の調査で検討すべき妥当な仮説をいくつか提示することにある。
結論
定性的なユーザビリティテストのデータ分析は、しばしば想像以上に複雑だ。この種のデータは豊かで、ニュアンスに富み、しかも雑然としているからだ。優れたアナリストは、適切なデータをもれなく収集し、多角的に評価し、データに合致する説明を探り、その説明が適切かどうかを検証するのである。
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。