定量的ユーザビリティテストと定性的ユーザビリティテスト
相互補完型のユーザー調査である両者は、反復デザインのサイクルで重要な役割を果たす。定性的な調査は、デザインプロセスに情報提供をする。一方、定量的な調査は、ベンチマークプログラムやROI算出のための基礎となる。
はじめに
ユーザビリティテストによる調査では、割り当てられたいくつかのタスクを1つ以上のデザインで参加者に実行してもらうことになる。しかしながら、そうしたユーザーテストによる調査で収集できるデータには、2つの種類がある:
- 定性データ:複数の観察結果から構成され、デザインが使いやすいか、使いにくいかを特定する。
- 定量データ:1つ以上の指標(タスク達成率やタスク時間など)の形式であらわされ、タスクが実行しやすかったかどうかを示す。
定性調査
定性データは、システムのユーザビリティの直接的な評価を提供する。定性調査では、リサーチャーは、参加者が特定のUI要素に取り組んでいるところを観察して、デザインのどの部分に問題があり、どの部分がうまくいっているかを推測する。彼らはいつでも参加者に補足の質問をすることができるし、調査の流れを変更して、参加者が直面している具体的な課題についての知見を得ることも可能だ。その後、リサーチャーは、自分たちの持つUXの知識と、場合によっては、他の参加者が同じ問題に遭遇した(あるいは、しなかった)という観察結果から、そのUI要素のデザインが本当に良くないのかどうかをそれぞれ判断する。
定量調査
定量データは、デザインのユーザビリティの間接的な評価を提供する。この評価は、所定のタスクに対するユーザーのパフォーマンス(たとえば、タスク達成回数、成功率、エラー数など)が基になることもあるし、参加者のユーザビリティに対する認識(たとえば、満足度など)が反映される場合もある。しかし、定量的な指標は単なる数字にすぎないので、基準点がないと解釈のしようがない。たとえば、調査参加者の60%がタスクを達成できた場合、その数値自体が良いものなのか、悪いものなのかを絶対値から判断するのは難しい。そのため、多くの定量調査では、サイトのユーザビリティの詳しい記述というよりも、既知の基準、あるいは、競争相手のユーザビリティや以前のデザインと、自分たちのサイトのユーザビリティとの比較をその狙いとしている。
定量データは、デザインが基準に対してユーザブルではない、という可能性を示すことはできるが、ユーザーがどんな問題に遭遇しているかを指摘してくれるわけではない。その上、次にもっと良い結果を得るには、デザインのどこを変えればいいかを示してくれることもない。参加者の40%しかタスクを達成できなかったということがわかっても、なぜユーザーがそのタスクに苦労したのか、また、どうすればそのタスクがやりやすいものになるかがわかるわけではない。そのため、リサーチャーはインタフェースの具体的なユーザビリティの課題を理解するために、定性的な手法を使って、定量データを補足しなければならないことが多いだろう。
統計的有意性
定量データの定性データに勝る強みの1つに、統計的有意性がある。定量データは、理にかなった表示方法で示されれば、偶然性をある程度防げるからだ。一般には、信頼区間や統計的有意差のような数学的手段によって、データが事実をどのくらい反映しているかを知ることができる。つまり、こうした手段によって、データがランダムなノイズによる結果にすぎず、ひょっとすると、たまたまリクルートした特定の参加者、あるいは、その調査が実施された条件のせいで起こってしまった結果ではないかどうかを伺い知ることができるというわけだ。ベテランの定性調査のリサーチャーも、優れたプラクティスという武器を投入して、偶然をなくし、結果にバイアスがかからないように力を尽くすだろう。しかし、定性調査の結果が実際に客観的なもので、ターゲット層全体を代表しているという正式な保証はないのである。
定性調査と定量調査の違い
定性データと定量データでは、調査のための設定が少し異なるし、かなり違う分析方法が必要になる。両者を同時に収集することはほとんどないので、定性的なユーザー調査と定量的なユーザー調査は別ものだといえる。とはいえ、定性テストも定量テストも、反復デザインのサイクルには不可欠なものだ。我々の業界では定性調査のほうがよく使われるが、変更したデザインについての数字を提供し、新バージョンが旧バージョンに比べてどのくらい改善されたかを明らかにできるのは定量調査だけだからだ。つまり、定量調査というのは、投資利益率の算出には欠かせない手段なのである。
以下の表に、この2種類の調査の違いをまとめた。この記事の残りの部分では、こうした両者の違いについて詳しく論じる。
| 定性調査 | 定量調査 | |
|---|---|---|
| 回答してもらう質問 | なぜ? | どのくらい? |
| 目的 | 形成的・総括的:
|
主に総括的:
|
| 利用するタイミング | いつでも:デザイン変更中でも、実際に動く最終版がある場合でも | (デザインサイクルの最初か最後の段階で)実際に動くものがある場合 |
| 成果 | リサーチャーの印象や解釈、事前知識に基づいた調査結果 | 別の調査でもおそらく再現可能な、統計的に有意な調査結果 |
| 方法 |
|
|
反復デザインのサイクル:定性調査と定量調査の目的
ユーザー中心デザインの基本サイクルでは、まず、既存デザインの評価(evaluate)をおこない、その後、その現システムのユーザビリティ上の課題に対応するためにデザイン変更(redesign)をする。そして、新しいバージョンが完成したら、それを評価して、最初のバージョンと比較(compare)してもよい。
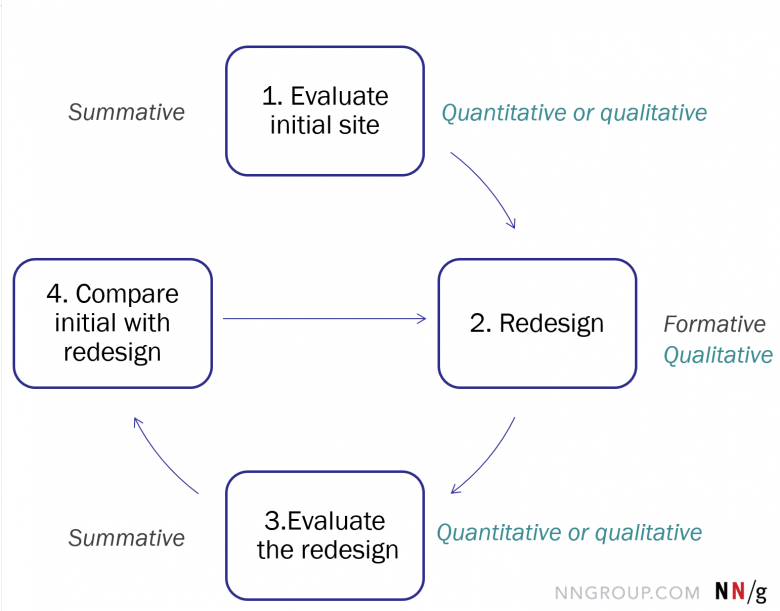
反復デザインのサイクルの1番目と3番目は、総括的段階で、デザインに対する総合的な評価の提供が目的となる。このステップでは、定性と定量の両方の調査手法(または、PURE(:専門家による実際的なユーザビリティ評価)のような両者を組み合わせた手法)によってデザインを評価する。とはいえ、デザイン変更という取り組み全体によって、実際にコストを削減したり、どのくらいデザインが改善したかを明確に割り出すとことを目指す場合は、定量調査を利用する必要がある。成熟したUXをもつ組織には、こうした定量的なユーザビリティ追跡プロセスを備えているところが多い。(デザインの各バージョンを定量的に評価し、それを旧バージョンと比較するプロセスは、ベンチマーク手法と呼ばれることもある)。
デザイン変更の段階において、ユーザー調査は形成的な役割を果たす。つまり、デザインに情報を提供し、デザインを正しい方向に誘導する。このフェーズでは、デザイナーとリサーチャーは、さまざまなデザイン案の中から選択をおこない、ユーザブルなUIを作り出すために、ユーザーデータを比較的早くかつ安く集める必要がある。したがって、この段階には、通常、定性調査が最も適している。(そのデザインがすでにほぼ完璧な状態でなければ)1つのデザインにつき、5人のユーザーがいれば、ユーザビリティの問題の85%を発見できるだろうということがわかっているからだ。そのため、デザイン変更のステップでは、数人のユーザーで簡単な調査を一度おこない、大きな問題を見つけ出して、それを解決し、その後、その新バージョンを違うユーザーで再度テストするとよい。
定性調査と定量調査の利用のタイミング
定性調査は、デザインの主要な問題を特定するのに適している。たとえば、ユーザーが入力フォームをうまく送信できない要因が(もしあるとしたら)何であるかを確認するのに、定性調査なら、すぐに実施できるからだ。そして、その調査を基にして、入力欄を大きくしたり、パスワードの要件を提示したり、入力欄の中ではなく、外にラベルを置いたほうがいいのか、といったことを決めればよい。
一方、定量調査は、完成版のサイトに対して、サイトのユーザビリティを評価する目的でおこなわれ、デザイン変更プロセスに直接情報を提供することはない。これは、デザイン変更のサイクル中は定量的な手法を使えないから、ということではなく、定量的なユーザビリティ調査は、デザインプロセス中に頻繁に、また、初期段階で実施するには、コストがかかりすぎるからだろう。一般的にいって、定量調査には多数のユーザーが必要だし、ページの広告文が見やすいか、とか、ボタンが見つけやすいか、といったことを調べる調査に大金を費やせる組織は多くない。しかしながら、定量テストから得られる数字は、サイトの全面的なデザイン変更をする必要があると、上層部を説得する場合には非常に有益である。
定性調査と定量調査の成果
定性データは、通常、調査結果のセットから構成されていて、デザインの長所と短所を明らかにするものだ(そして、深刻度による優先順位もつける)。しかし、こうした調査結果は推定によるものであり、タスクを進行させ、ユーザーの行動の意味を解釈するリサーチャーの知識や経験度に左右される。同じユーザーテストのセッションでも、やる人が変われば、別の課題が特定されることはよくある(この現象は評価者効果と呼ばれている)。さらに、ターゲット層に合う参加者を慎重にリクルートしたとしても、調査に参加するユーザーは数人だけなので、彼らがユーザー層全体を真に代表していないという可能性も常にあり、そうなると、調査結果は偏ったものになってしまう。
一方、定量調査は、通常、大量のユーザーを対象とし(30人以上であることが多い)、そうした偶発的な出来事を防ぐために統計的手法を利用する。また、正式な報告の場合、定量調査には、結果の統計的有意差に関する情報が盛り込まれることになる。たとえば、誤差の範囲によって、調査の結果をどのくらい信頼していいかを理解することが可能だ。また、自分のサイトと競合サイトとのタスク達成時間の差が統計的に有意であれば、違うユーザーをリクルートして、調査をやり直したとしても、調査結果は同じ傾向になるだろうことがわかる。それぞれの正確な平均値は少し違うかもしれないが。
したがって、定量調査は正確に実行され、分析されれば、結果の正当性を信じることができる。すなわち、サイコロの結果のような、運によるものではないと確信できるのである。
こういう種類の分析は統計学が基礎になるので、定性的なユーザビリティリサーチャーが持っていない種類のスキルが必要なことが多い。そのため、多くの企業では、定量担当と定性担当のUXリサーチャーの職務要件を別にしている。
定性調査と定量調査の方法
定量的なユーザーテストと定性的なユーザーテストは、表面的には非常に似ている(すなわち、両方とも、ユーザーにデザイン上でタスクを実行してもらう必要がある)。また、どちらの種類の調査も、適切な実験デザインの基本ルールを守るべきであり、以下の妥当性を必ず確保する必要がある:
- 外的妥当性:参加者がターゲットオーディエンスを代表していて、タスクが自然な状態でおこなわれる場合のやり方が調査条件に反映されている。たとえば、モバイルサイトをデスクトップシミュレーターでテストすると、外的妥当性は損なわれる。なぜならば、ユーザーは普通、タッチスクリーン付きのスマートフォンでそうしたサイトを利用するからだ。
- 内的妥当性:実験の設定がどれか1つの案に有利な条件になっていない。たとえば、デザインAのテストは午前中で、デザインBのテストが午後だと、参加者がデザインBを利用する際には疲労による影響が出てしまう可能性がある。
しかし、定量調査は統計的に有意な結果を得ることを目指すものなので、この2つの調査には重要な違いもある:
- 前述のとおり、定量調査は定性調査よりも多くのユーザーを必要とする。
- セッションの設定や参加者の環境が異なると、測定ノイズが増えて、結果的に誤差の範囲が広がってしまうので、定量調査では、可能な限り、ばらつきを抑えることが目標になる。したがって:
- 定量調査は、セッション間で条件を厳しくコントロールする必要がある。すなわち、参加者が可能な限りほぼ同じ環境でテストをおこなえるようにしなければならない。つまり、2セッションはユーザーに直接会って実施し、3セッションはリモート形式でおこなう、というようなことはしてはならない。
- 定量調査は、参加者全員に調査の設定や評価するサイトに慣れてもらうための、練習用タスクから始まることが多い。これにより、たとえば、エキスパートユーザーと初心者の間にあると考えられる個人差を調整することができる。初心者がインタフェースを学ぶ機会を得られるからである。
- 思考発話法は、定性調査では定番的な手法になっている。しかし、定量調査には推奨できないこともある。思考発話プロトコル法を定量調査に使うことが正しい判断なのかどうかについてのリサーチャーの意見は分かれている。口数の多さというのは、人によって、ある程度違うものなので、この手法を使うことで測定ノイズが増えるとも考えられるからだ。その結果、多くの定量調査では、参加者に思考発話を要求していない。
- 名前や住所、誕生日のような個人情報は調査のばらつきを増加させる。なぜならば、人によってデータは違うからだ。定性調査の場合は、ユーザーは彼ら自身の本当の情報を入力することを依頼されるが、定量調査では、全員のエクスペリエンスが同じになるべきなので、皆がまったく同じ文字列を入力しなければならない。そのため、参加者には全員が利用可能な架空のデータセットが提供される必要がある。(この制約のために、実際のシステムのバックエンドに問題が生じることもあるだろう)。
- 逆に、定性調査では、セッションによって調査条件が違っても問題はない。たとえば、あるタスクからは必要としている知見が得られないとわかれば、次のユーザーのテストをおこなう前に、そのタスクを何としてでも書き直したほうがよい。タスクを変更すると、異なるタスクを実行したユーザー全体の指標の平均値には意味がなくなる。しかし、定性調査の目的は知見を得ることであり、数字を得ることではないので、(そもそも、この調査の目的というわけではない)数値の価値を損なうことになる変更であっても、思い切ってやればよいのだ。
- 定量調査のタスクの答えは1つのみで、明確でなければならない。したがって、「John Smithさんの電話番号と住所を探してください」といったタスクは、定性調査にはふさわしいかもしれないが、定量調査には適さない。何をもってタスクの成功とするかが難しいからだ。たとえば、ある参加者が電話番号は見つけたが、住所は見つけられなかった場合、それは失敗と見なすべきだろうか。
また、タスクを読んだときに理解する内容が、参加者全員で同じである必要もある。たとえば、「カリフォルニア州でドローンの飛行許可を得るための要件をリサーチ(research)してください」といったタスクは、定量的なユーザー調査で使うには曖昧すぎる。「リサーチ」という言葉の解釈が人によって違うかもしれないからだ(:researchは、研究する、調査するなどの複数の意味をもつ)。しかし、ユーザーがどんな種類の情報に興味があるのかを明らかにしようと思う場合に、このタスクを定性調査で使うのは問題ないだろう。 - 定性的な実験でも、定量的な実験でも、タスクをランダム化するというのは優れたプラクティスだが、定性調査は完全にはランダム化できないことが多い。しかし、定量テストでは、ランダム化により、タスクの順番による結果へのバイアスをまったくなくすことができる。
結論
定性的なユーザビリティテストと定量的なユーザビリティテストは、目的の異なる相互補完的な手法である。定性テストは、少数(5~8人)のユーザーでおこなわれ、インタフェースにある主要なユーザビリティの問題を直接特定する。形成的に利用されることが多く、デザインプロセスに情報を提供して、プロセスを正しい方向に導く。一方、定量的なユーザビリティテスト(ベンチマーク手法)は、多数の参加者(30人以上であることが多い)が基になるので、分析と解釈が正確におこなわれれば、テスト結果にランダムなノイズの影響を受けにくい。定量調査は、タスク達成率やタスク時間、満足度のような指標をとおして、サイトのユーザビリティの間接的な総括的評価を提供するもので、デザイン反復中のシステムのユーザビリティの追跡のために通常、利用される。
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。