AIモデルはどう訓練されているのか
現在のLLMの訓練は、モデルの出力をかたちづくる高コストなプロセスであり、教師なし学習・教師あり学習・強化学習を含むものである。
これまでに、お気に入りのAIツールの背後にある大規模言語モデル(LLM)が「インターネット全体で訓練」されているという話は、間違いなく耳にしたことがあるはずだ。それはある程度事実だが、数百人のUX専門家にAIの業務活用法を指導してきた私の経験から言って、多くの人がAIの訓練「方法」を理解していないことは明らかだ。この理解はLLMの仕組み・限界・能力についての正確なメンタルモデルを形成する上できわめて重要である。
この記事では、4つの基本的な訓練の種類、LLM内でのその実施のタイミング、そしてそれらがユーザーエクスペリエンスにおけるAIの役割に与える影響について説明する。
1. 事前学習フェーズ:教師なし学習
大規模言語モデルが「インターネット全体で訓練された」というとき、通常、それは教師なし学習を用いる事前学習フェーズのことを指す。
このフェーズでは、モデルに、インターネット、デジタル化された書籍、コードリポジトリなどから収集した膨大な量のテキストやデータを与える。Common Crawlはこうしたデータセットの1つで、数十億のウェブページから収集したテラバイト級のデータセットだ。こうした大規模データセットの使用前のクリーニングには多大な労力を要する。
データの量が莫大であるため、人間がそのすべてにラベルを付けたり説明したりすることは不可能だ。代わりにモデルは、系列における次の単語(「トークン」)を予測しようとすることで、自らパターンを学習する。
数十億もの例の単語の組み合わせに触れることで、モデルは文法や事実、(ある種の)推論能力、さらにはデータに存在するバイアスさえも学習する。
事前学習フェーズでは、AIモデルは、特定のタスクや人間的な意味での「意味」を学んでいるわけでは「ない」。学んでいるのはほぼすべて統計的な関係であり、さまざまな文脈において、どの単語が他の単語に続きやすいか、ということである。
教師なし学習は幼児のようなものだ
教師なし学習は、生後2年間、言語に浸っている幼児のようなものだと考えるとよい。彼らは無数の会話を耳にする。すべての文法規則を明示的に教わるわけではないが、次第にパターンを吸収しはじめる。
やがて、彼らは聞いた言葉を真似て単語をつなぎ合わせはじめ、ときには、直接教わったわけでもなく、その意味を完全に理解していない文で、あなたを驚かせることもある。
AIベースのデザインにおける教師なし学習
モデルによって、用いる訓練データの種類、学習するパターン、出力を生成する際にこれらのパターンに依拠する方法は異なるが、原理は同じである。
例としてFigma AIを取り上げよう:その生成AI機能には、確固たる基盤として大量のトレーニングデータが必要だ。ただし、ゼロから始めてまったく新しいモデルにFigmaで作成された多くのデザインを与えて事前学習させるわけではなく(これは重大なプライバシー問題を招き、コストも極めて高い)、「サードパーティのすぐに使用できるAIモデル」を用いている。これらのサードパーティモデルは、OpenAIのようなより堅牢なAI企業のAPIを呼び出す。
では、テキストで事前学習したモデルに依存しているのに、Figma AIはどうやってユーザーインタフェースを生成できるのか。彼らが使っている事前学習用データセットは非常に膨大であるため、こうしたモデルは何十億行ものコードを処理し、インタフェースの組み立て方のパターンを学習している。しかし、これは「最近の売上データを表示するダッシュボードを作成して」と指示したときに、有用で、アクセシブルで、妥当なものが作られることを保証するものではない。それには微調整が必要なのである。
2. 微調整フェーズ:教師あり学習
事前学習フェーズがモデルに生のパターンを教えるのだとすれば、微調整フェーズ(教師あり学習を用いて)は、特定のレッスンを行い、例を与えるようなものだ。
いまや幼児は成長し、学校へ送り出す段階だ。そこでは教師から正しい文と誤った文の例が大量に示される。これらの厳選された例は、教師なし学習で習得した膨大な語彙をどう用いるのかをその子どもに教えるためのものだ。
AIモデルを訓練するため、リサーチャーは入力(プロンプト)と望ましい出力(応答)の入念に作成された例を含む、事前学習よりはるかに小規模なデータセットを作成する。
たとえば、リサーチャーは特定のプロンプトを作成し、モデルに模倣させたい理想的な応答と組み合わせる。さらにその応答の複数のバリエーションを作り、有用性・明確さ・安全性といった基準で評価することさえある。こうした入念に作成した数千例をモデルに提示することで、モデルが事前学習で見いだしたパターンを、人間の期待に沿う、有用で正確な方法で用いるよう教えるのだ。なお、リサーチャーは依然としてすべてのガイダンスを入力側で与えており、この段階ではAIの出力そのものにはまださほど注意を払っていない。

教師あり学習のデータセットは教師なし学習用よりもはるかに小規模だが、作成には多大な人的労力とコストを要する。このフェーズはモデルを特化させ、指示に従う能力を向上させるうえできわめて重要である。
しかし、ここでもバイアスは入りうる。事前学習に用いられるデータには、すでに社会的バイアス(たとえば、特定の属性や見解がオンラインで過剰に反映されていることに起因するもの)が含まれている。さらに、微調整では、人間が作成し評価した具体例によって、「評価者」の視点や価値観、潜在的バイアスも持ち込まれる。
ラベリングデータのチームが異なれば、モデルに刷り込まれる「作法」も少しずつ異なりうる。これが、同じ膨大なデータで訓練されたLLMであっても、トーンや性格、アプローチが異なってくる理由の1つだ。微調整の仕方がわずかに異なるからである。
AIベースのデザインにおける教師あり学習
教師あり学習はチャットボットだけのものではない。Figmaでさえ、出力を改善するためにAI機能のいくつかを微調整している。ただし、Figmaが言及しているのは「ビジュアル検索」「アセット検索」「インタラクション追加」といった機能のみで、Text to UI(テキストからUI生成)機能である「First Draft(ファーストドラフト)」や「AI Prototyping(AIプロトタイピング)」には言及していない。
Figmaの微調整には「公開されている無料のコミュニティファイルのデータ」が使われている。つまり、この微調整は同社の従業員が作成または精査した高品質なデザインではなく、自由に利用できるデザインに依拠している。これは安価で迅速で、プライバシー制限にも違反しない理にかなった手法だ。ただし、先ほどのたとえに戻ると、その幼児の「教師」は、専門家が設計したカリキュラムではなく、インターネット上の無料の例を利用している、ということになる。
これはFigma AIが有用なものを何も生み出せないことを意味するのではない。単に、出力が無料の公開ファイルで利用可能なパターンに強く偏っているということだ。出力が凡庸だと感じられても驚くには及ばない。Figma自身も「デザインの概念やパターンをより深く理解するモデルを訓練する必要がある」と述べている。
UI作成用AIツールが専門デザイナーによって慎重に微調整されてはじめて、AIが生成するUIデザインは、現在のAIが生成した言語に見られるニュアンスの豊かさに匹敵するレベルの表現力を持つようになるだろう。
3. 高度な微調整:人間のフィードバックによる強化学習(RLHF)
この最後の訓練は、モデルの出力を人間が判断する高度な微調整手法だ。いまや子どもは(教師なし学習で)吸収した語彙を用いて、(教師あり学習で)教わった規則と例に従って作文の練習をしている。教師はその作文にフィードバックを与え、子どもはその場のフィードバックにもとづいて自分のやり方を調整していく。
人間のフィードバックによる強化学習(reinforcement learning with human feedback; RLHF)もこれとほぼ同じだ。人間がAIモデルの出力に基づいて指導を行うが、成功基準の定義が難しい場合には、出力に対するその人の感じ方が指針になることが多い。一方、成功基準が明確で、その基準の信頼性が高いタスク(例:ロボットタクシーが衝突せずに所定の目的地へ安全に到達する)では、AIモデルは成功か失敗かにもとづいて自律的に反復学習をすることができる(このプロセスを単に強化学習と呼ぶことが多い)。
では、成功が、良い/悪いや有用/非有用といった単純なルールで容易に定義できないとき、何が起こるのか。
RLHFは、強化学習のプロセスに人間を関与させる。モデルがプロンプトに対して複数の応答を生成すると、人間のラベラーにこれらの応答のどちらが優れているか、より有用か、より無害かといった観点から順位づけを求めるのである。
LLMを使用中に複数の回答案を提示されたことがあるなら、あなたはすでにRLHFに関わっていたということだ。実ユーザーからこの種のフィードバックを集めることで、AI企業はユーザーの選好を反映したフィードバックを大量に集めることができる。
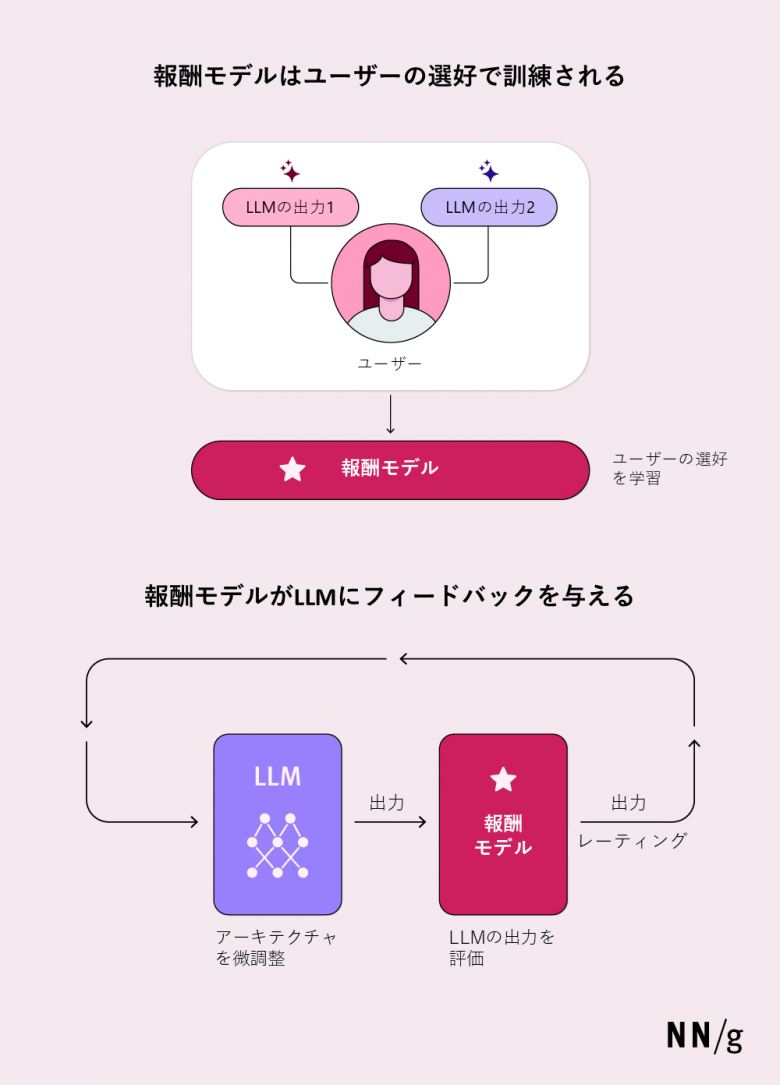
重要なのは、この人間の選好データがメインのLLMに「直接」報酬や罰を与えたりするために使われるのではない、という点だ。代わりに、このデータは別の報酬モデル(選好モデル)を訓練するために使われる。
この報酬モデルは、人間がどのような応答を好む傾向にあるかを予測できるよう学習する。その後、メインのLLMはこの報酬モデルを指針として用いて、報酬モデルが高くスコアづけする応答を生成しようとする。要するに、報酬モデルは、人間のフィードバックからパターンを学習してゲームのルールを作り、メインのLLMがそうしたルールにどれだけうまく従ってプレイできているかをスコアづけするのである。
繰り返しになるが、バイアスは懸念材料だ。フィードバックを提供するグループが多様なユーザー層を代表していない場合、そのグループの好みやバイアスがモデルの振る舞いに不均衡な影響を与えてしまうことになるからだ。これは現時点でも言えることだ。というのも、ほとんどの技術と同様に、AIの普及はあらゆる属性で同じように進んでいるわけではないからである。
AIベースのデザインにおけるRLHF
ウェブサイトのチャットボットや、カスタマーサポートの通話用のインタラクティブな音声応答システムなど、ユーザー向けのAIプロダクトの構築に携わっているなら、モデルがユーザーに有用な応答を提供できるようにするために、RLHFは絶対に不可欠だ。たしかに、教師なし学習で、そのようなシステムに自社の製品やサービスを理解させ、教師あり学習で、適切な応答例を教えることはできる。しかし、あなた方はユーザーではない。モデルが「何を言うべきか」について、チームが与えられるフィードバックには限界がある。また、製品とやり取りする実ユーザーの反応を考慮に入れ、応答を継続的に洗練させていく必要もある。
こうしたサービスを外部ベンダーが販売する場合も、社内で開発する場合も、実ユーザーが出力に対してどう評価するかに基づいて応答を継続的に微調整できる何らかの報酬モデルをあらかじめ計画しておく必要がある。
LLMは検索エンジンとは異なる
これはUX担当者が最も混乱する点の1つだ。
検索エンジンは既存情報を取得する
検索キーワードを入力すると、検索エンジンはウェブページや文書のインデックス化されたデータベースを検索し、最も関連性の高い「既存の」コンテンツを見つけて順位づけする。そして、それらの情報源をユーザーに示す。一方、データベースに該当する情報がなければ、回答を返すことはできない。
大規模言語モデルは新しい情報を生成する
LLMにプロンプトを与えると、訓練中に学習した統計的パターンを用いて、最も関連性の高い応答を形成すると考えられる単語の順序を予測する。これは確率にもとづいて単語単位で回答を構築する行為であり、データベースから事前に書かれた回答を呼び出すものではない。
この生成的な性質こそが、LLMがハルシネーション(自信を持って誤った情報を述べる現象)を起こす理由だ。LLMの第一の目標は、プロンプトに関連するもっともらしく感じられる単語の系列を生成することであり、必ずしも訓練データ(誤りが含まれている可能性がある)に存在する検証済みの真実を述べることではないからだ。一部の新しいAIツールでは、回答生成前にリアルタイム情報を取り込むために、(検索強化生成やRAGと呼ばれる手法を通じて)検索結果を統合するが、LLMの回答の核心部分は依然として生成されるものであり、取得されるものではない。
環境コストと労働コスト
AIモデルの訓練と運用には多大なコストが発生する:
- 環境コスト。教師なし学習による大規模モデルの訓練には、莫大な計算能力が必要だ。数千の専用プロセッサを数週間から数ヶ月にわたって稼働させ、大量の電力を消費し、二酸化炭素排出の要因となる。また、あなたや私のようなユーザー向けにモデルを稼働させるだけでも、特にこうしたサービスの運用規模では、エネルギーを消費する。
- 労働コスト。教師なし学習は人間の直接的なラベリングに依存しないが、人間のフィードバックによる強化学習や、少なくとも一部の教師あり学習は、人間の労働に大きく依存している。世界中で何千人もの人々が、訓練例を作成し、プロンプトを書き、モデルの応答を評価し、有害なコンテンツをチェックするために雇用されている。このデータラベリング作業は、しばしば外部委託され、低賃金なこともある。そして、作業では、センシティブだったり問題のあるコンテンツに触れる恐れもある。これは、AIを動かす原動力となっているきわめて重要な知的労働の就労条件と報酬について、倫理的課題を提起するものである。
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。