テキストマイニング
テキスト(文章)を単語レベルまで分解し、単語同士の関係や、性・年齢などの属性やアンケートなどの回答、テキスト発生時期などとの関連を分析します。
テキストマイニングとは
テキストマイニングは、テキスト(文章)で蓄積されたデータを、コンピューターを用いて、単語レベルに分解して、有用な知見を得るためにさまざまな統計手法で分析するものです。その際に、単語同士の関係などのほか、性別や年齢など、アンケートで回答した内容など、さまざまなものとの関連性を分析します。
何ができるか/ご利用想定シーン
- 評価意識の推定
特定の製品やサービスについての、気になる点などの自由文での回答を収集し、その製品に対する評価が、チャネル、価格、安全性、提供者のブランドイメージなど、どのようなものが出ているか統計処理を行います。
その自由文の統計データに関して、性・年齢別や他の回答との関連性を、主成分分析や、コレスポンデンス分析など、各種の分析手法を用いて分析することで、仮説の検証や、新しい知見を得るなどを行います。 - 評価意識の推定以外の例
時系列で収集した文章を分析することで、内容の変化を知ることができます。特定のWebサイト内での、話題や関心事の推移などをみることのほか、絶対数が少なくても急増している話題などを抽出することもできます。
イードのテキストマイニングの特長
- 蓄積されたノウハウで、最適な調査・辞書作成を実施し、テキストマイニングソフトだけでなく、各種分析ソフトとの連携で多様な分析を実現
- イードでは2001年に、ジャストシステムのテキストマイニングソフトであるコンセプトベース 「クラスタリング」と「クラシファイア」を導入し、早くからテキストマイニングに取り組んできました。
- さらに2004年には、野村総合研究所のTRUE TELLER(トゥルーテラー)を導入し、単語の出現状況や相関関係などの解析も容易にできるようになり、またネットワーク図や散布図などのご提供もリーズナブルにできるようになりました。
- テキストマイニングの成功は、「適切な調査・設問の設計」と「適切なユーザー辞書」に大きく左右されます。
- イードでは、長年の多分野でのコンサルティング・リサーチで培った専門知識を有する社内人材のノウハウから、「各プロジェクトに最適な」「調査・設問の設計」ならびに「ユーザー辞書」作成をいたします。
- また、テキストマイニングの結果をSPSSをはじめとする他の分析ソフトで、更なる分析を行うことも可能です。
アウトプット例
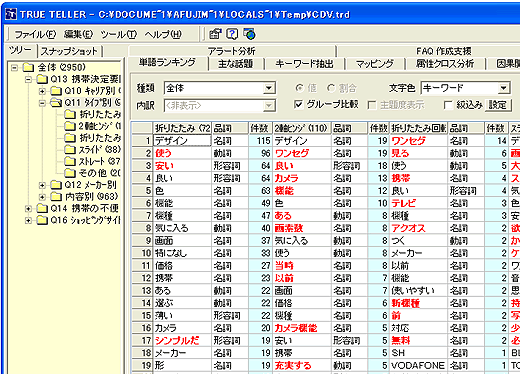
単語ランキングの例:携帯電話の購入決定要因(タイプ別)
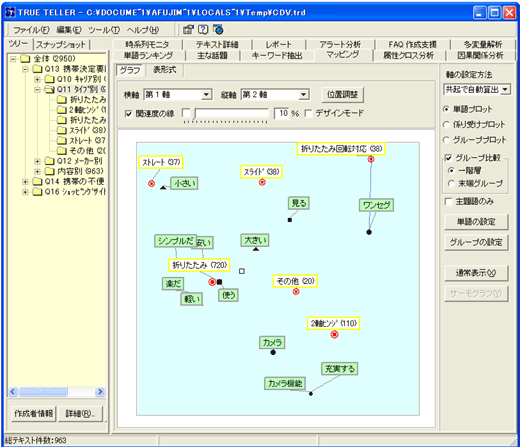
マッピングの例:携帯電話の購入決定要因のキーワード(タイプ別)