
情報アーキテクチャにおけるカテゴリーの例外への対処法
ユーザーの概念カテゴリーのメンタルモデルは、思っているほど厳密ではない。例外ページはより大きな親カテゴリー内に少数だけ置くことにして、不要なサブカテゴリーを作らないようにしよう。
Webサイトやアプリの情報アーキテクチャの構築に携わったことがある人なら、少し厄介な要素に遭遇したことがあるのではないかと思う。その要素とは、そこに収容されるのが自然に感じられる居場所が複数あったり(ポリヒエラルキー)、1つのカテゴリーに「ゆるく」収まっているものだ。そして、そうした状況にどのように対処するか迷って、その半端な要素のために専用のサブカテゴリーを作成するべきか、それとも「何となく」属しているカテゴリーに入れたままにしておくべきなのかを自問したことがあるのではないだろうか。さらに、どのくらい「厳密に」あるいは「論理的」にカテゴリー分けをする必要があるのかという観点からそうした要素について検討したこともあるかもしれない。
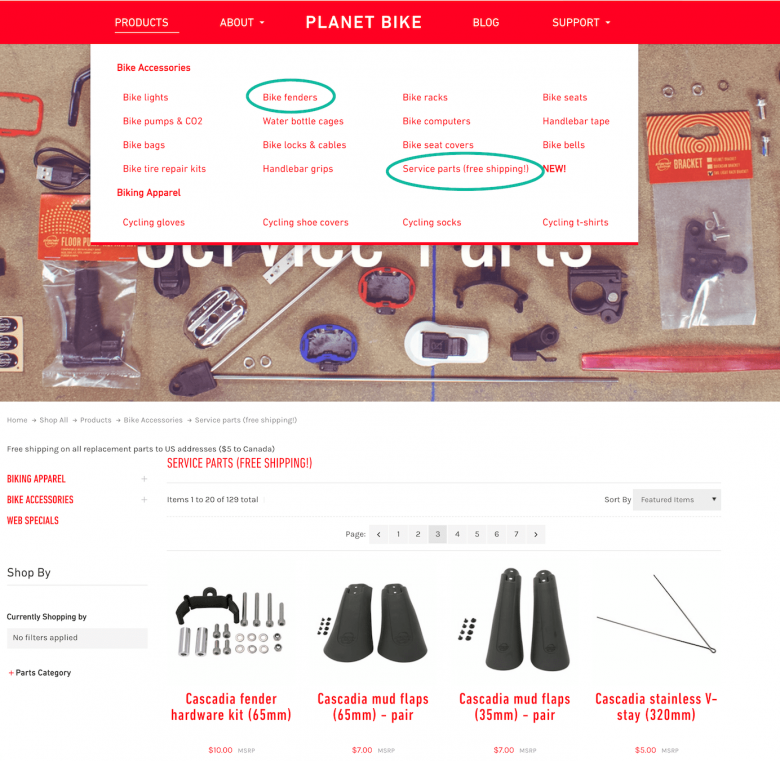
情報アーキテクトは、要素が同じカテゴリーに属するにはどのくらい類似している必要があるのか、逆に、カテゴリーを分けるためにはどのくらい違うべきなのかについて悩むことが多いのである。
カードソーティングは予期していなかったグループを浮かび上がらせる
カードソーティングは、情報アーキテクチャのプロジェクトでよく利用される調査手法だ。この手法は、ユーザーに対象物(カード)を彼らが理解できる束にグループ分けしてもらうというものである。もし大部分のユーザーがあるオブジェクトを同じ束(つまり、カテゴリー)に入れれば、そのオブジェクトは最終的な情報アーキテクチャでそのカテゴリーに入れても問題ないというわけだ。
カードソーティングのデータの分析は、しばしば困難を伴う。第一に、参加者によって、結果にかなり違いがあるからである。
そして、第二には、大部分のユーザーが合意する枠組みにきちんと当てはまらない例外のカードがよくできてしまうことによる。
カードソーティングをすると、例外の要素にゆるく関連のあるカテゴリーは判明することが多い。しかし、例外の要素のそのカテゴリーへの帰属の度合いは、そのカテゴリーに属す他の要素と比較すると弱いものだ。(言い換えると、例外の要素がそのカテゴリーに入ることを表明した参加者もいたが、その人数はそのカテゴリーの他の要素ほどは多くない)。このような場合、情報アーキテクトは、例外の要素が、(1)関連性の弱いメインカテゴリーに(もしかするとこの要素専用のサブカテゴリーとして)属すべきか、(2)まったく別の独自のカテゴリー(または(1)と両方)に属すべきか、を決定する必要がある。
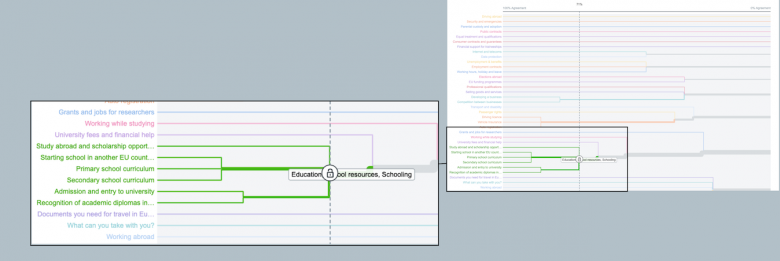
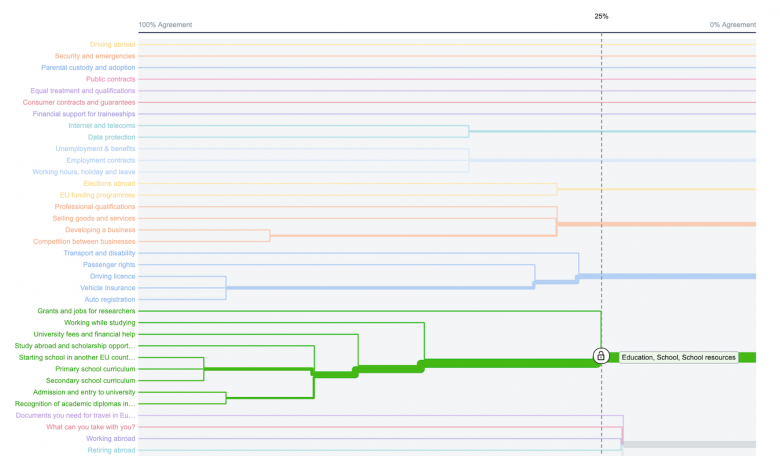
場合によっては、他の要素とほんの少し異なる1つか2つの要素のためにサブカテゴリーを作成するかどうかが問題になることもあるし、以下のように、調査参加者が我々の予想とはまったく違う要素同士を一緒にしていて非常に驚かされることもある。

ここでは、情報アーキテクトは、「教育」の例とは微妙に異なる判断をしなければならない。「動植物」はこのグループの(観光や文化的な観光スポットに関連する)他の要素とは概念的に少し異なるので、考えられる選択肢は以下のようになる:
- これらの要素をサブカテゴリーのない1つのカテゴリー(たとえば、「おすすめポイント」、「EU観光」など)にまとめ、現地の動植物に興味のある人がここでそうした情報を探してくれることを期待する。
- 上と同じ(「おすすめポイント」のような)広範な包括的カテゴリーを置きつつ、あわせて以下のどちらかの方策を取る:
- そのメインカテゴリーのコンテンツを「文化」と「屋外」というサブカテゴリーに分割する。
- または、メインカテゴリーにほとんどのものを残し、「動植物」だけをサブカテゴリーに入れる。
- 「文化」というトップレベルのカテゴリーを作り、さらに「屋外」というカテゴリーを別に置く。
- 要素を複数のカテゴリーに入れて、どちらのリストでも見られるようにクロスリスト化する(軽いポリヒエラルキーの一種)。
さて、情報アーキテクトはどうすればいいだろうか。
分類理論:人間は(厳密には)合理的ではない
カテゴリーの例外をどうすべきかを考える場合には、人が物事をグループ化する際、どういうことが起こるか、というところまで戻って理解するとよい。
まず、人はカテゴリー間に確固たる論理的な境界を作り、その確固たる境界はグループ化されたすべての要素の「共通の特性」によって定義される、という一般的な仮定を改めてもらえたらと思う。この暗黙の了解は論理的ではある。しかしながら、真実ではない(ここでは、科学や法律などで出てくる形式的な分類や定義の設定のことではなく、ユーザーが自分のメンタルモデルで頼りにする直感的な分類のことを言っている)。
たとえば、サイエンスフィクション(SF)とは何だろうか。その名が示すように、科学に関連しているフィクションということだろうか。だが、SFが科学に基づいていないのは明らかだ。『スターウォーズ』は、とてもおもしろいSFだが、我々が知っているように、しょっちゅう物理の法則を破っている。では、未来が舞台になっているものということだろうか。『宇宙空母ギャラクティカ』(訳注:米国のSFドラマ。宇宙戦争後、人類が帰還した地球は、彼らよりはるかに文明が遅れている西暦1980年だった)がその偉大な反例だろう(さらに言うと、『スターウォーズ』もそうだ)。なら、宇宙が舞台ということか。いや、N. K. ジェミシンの『破壊された地球』三部作は、そうした思い込みを打ち消すものだ、などなど。
では、人はどのようにカテゴリーを形成するのだろうか。言語学者や認知科学者は、「家族的類似」という概念を中心にしたモデルを作り上げてきた。家族には確かに共通の特徴(顔の特徴、好みなど)がある。しかし、家族の全員がその同じ特徴をもっているわけではない。家族の類似性は程度によるもので、家族で共通してもっているそれぞれの特徴ごとに連続体になっていて、「はい」か「いいえ」という二元的なものではない。
さらに、ユーザーは、新しく追加する要素がそのカテゴリーの既存の要素とは異なるものであっても、新しい要素をカテゴリーに追加して、そのカテゴリーの境界を拡張してしまうこということをよくする。よく知られているように、「ゲーム」というカテゴリーの境界は、1970年代にテレビゲームが登場したときに大きく変化した。このように、カテゴリーを構成する要素のすべてがある1つの決まった特徴のセットを共有する必要はない。
もう1つの重要な概念として、カテゴリーの要素には中心になるものと中心にならないものがある、というものがある。人は、カテゴリーのある要素を他の要素よりもそのカテゴリー全体に対するより典型的な要素であると考える。たとえば、もし、私が宇宙人に自動車とはどういうものであるかを教えたいと思って、彼らにパパモビル(:ローマ教皇の一般拝謁用の車)の写真を見せたとしたら、あなたは笑って、私のことをあまり良くない先生だと思うだろう。しかし、パパモビルが自動車であることにはほぼ確実に同意してくれるはずだ。とはいえ、奇妙で、普通の自動車ではないが。カテゴリーの非中心的な要素もそのカテゴリーの要素として認識するのはまだ比較的容易だ。しかし、同じカテゴリーの中心的な要素ほど容易に認識できるわけではない。この違いが重要である。カテゴリーの非中心的な要素もカテゴリーに属することはできる。しかし、そのカテゴリーの最良の例ではないということだ。

興味深いのは、「概念的には」あるカテゴリーの非中心的な要素だからといって、その要素が人気がないとは限らないことだ。たとえば、2020年にアメリカで最も売れた車は、フォードFシリーズのピックアップトラックだった。ピックアップトラックは、「自動車」という概念カテゴリーにおいては中心的な要素ではない。しかし、このフォード車は(ほとんど誰がみても、直感的に「自動車」というカテゴリーのかなり中心的な要素に思える)トヨタカムリよりも91%も販売台数が多かった!
では、情報アーキテクチャにある例外という問題に対処する方法に戻ろう。この問題については、最も理にかなっていることを主に定性的な観点から判断すればよく、カードソーティングで出たパーセンテージの違いを心配しすぎる必要はない。また、ここでの意思決定はビジネス上の優先順位をしっかり反映していることが重要だ。そして、概念的には階層の深いところに配置すべきものであっても、それがビジネスやユーザーにとって非常に重要なものなら、より上の階層に移動させて、ユーザーの目につきやすいようにするかもしれない。
アプローチ1:例外をナビゲーションのサブカテゴリーに配置する
カテゴリーの例外という問題に対するアプローチの1つは、特定したその例外専用の、より具体的なサブカテゴリーを作成することだ。このアプローチには、非常に「具体的な」要素を探し求めている人が、検討すべき要素のリストを絞り込める、という利点がある。
この場合、基本的には、カテゴリーの非中心的な要素をグループの残りの部分から分離する。このアプローチは、その例外が大きなカテゴリーと家族的類似性が比較的低い場合に最も有用だ。そうした例外を大きなカテゴリーに入れてしまうと、カテゴリー名をより一般的なものにせざるをえなくなり、情報の匂いが弱まるからである。先ほどのEU観光サイトの例に戻ると、「動植物」を文化的、歴史的観光スポットと同じメインカテゴリーに入れるのであれば、そのカテゴリー名は、「文化」よりも情報の匂いが弱い「おすすめポイント」のようなものにする必要があるだろう。
親カテゴリーの情報の匂いを弱める以外にも、このアプローチには、情報アーキテクチャが深くなり、ユーザーが検討しなければならないサブカテゴリーがたくさんある(そして、そうしたカテゴリーの中には、ほとんどのユーザーにとって区別がつかないものもある)、という欠点がある。一般に、階層が深くなるほど、浅い場合に比べてページ移動が難しくなるし、具体的なサブカテゴリーは、前述の基本的なカテゴリーよりも高度な認知的努力が必要だ。
また、こうした具体的なサブカテゴリーは、最終的にはごくわずかな要素しか入るものがないという可能性もある。だからといって、この世の終わりというほど深刻な状況ではないが、こうしたやり方は堅牢なコンテンツ戦略とは言えないだろう。
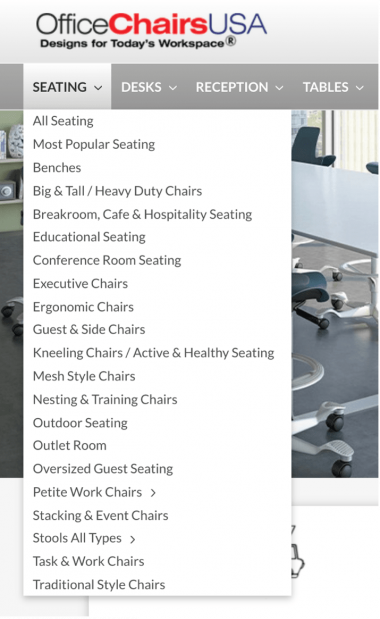
アプローチ2:例外をメインカテゴリーに残し、メタデータによって代替探索行動をサポートする
別のアプローチとして、カテゴリーの例外の要素を、普通ならそれが属しているであろう少し大きなカテゴリーに残しておくことも可能だ。このアプローチは、例外の数が比較的少なく、メインカテゴリーの要素と家族的類似性が高い場合に有用である。
このアプローチがほとんどの状況で有効であることにはいくつかの理由がある:
- 前述のように、カテゴリーの境界に関するユーザーのメンタルモデルは厳格ではなく、家族的類似性の度合いに基づいている。したがって、家族的類似性が高い例外なら、大きなカテゴリーに配置されていても、ユーザーが見つけ出せる可能性が高い。
- そうした例外は、さまざまな種類の要素が含まれる大きな親カテゴリーに置かれることになるため、発見しやすさが向上する(すなわち、こうした選択肢を探し求めていないユーザーも、カテゴリーリストを解析しているうちにこの例外を偶然発見できる可能性がある)。
- この例外への代替経路(たとえば、より構造化されたカテゴリー階層まで調べることができる、概念のバックエンド分類法を用いた堅牢な検索)を利用して、例外が入っているカテゴリーで例外を探そうとしないユーザーをサポートすることができる。
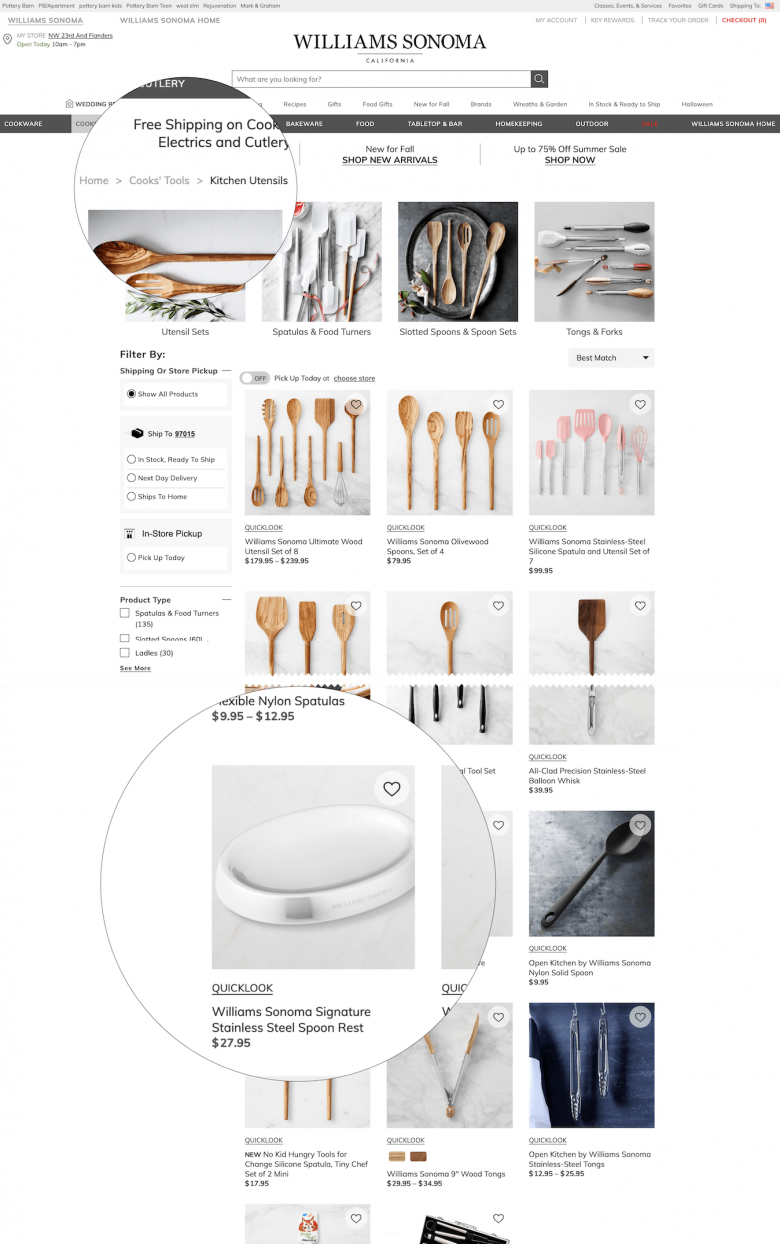
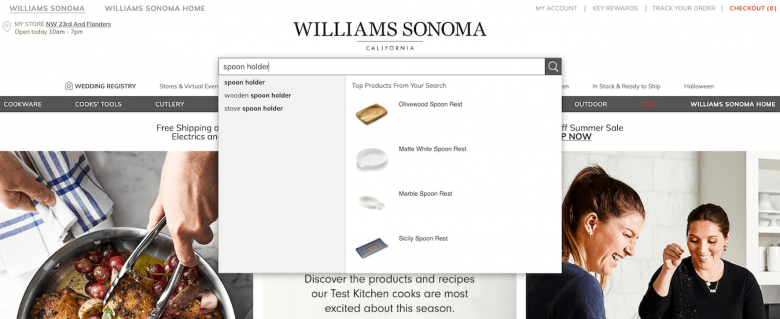
アプローチ3:両方の階層でポリヒエラルキー化する
例外は、前述の両方の手法、すなわち、独自のサブカテゴリー内に配置し、「さらに」メインカテゴリーにも配置することで適切にサポートできることが多い。ただし、このやり方には、例外のために新しいサブカテゴリーを作成するときと同じ大きな限界がある。つまり、該当する要素が少ない曖昧なカテゴリーができてしまう可能性がある。

要約
カテゴリーの例外は、情報アーキテクチャで複数の方法で対処することが可能だ。独立した専用のサブカテゴリーを作成して格納しようとすると、該当する要素が少なく、ユーザーからみると内容がよくわからないサブカテゴリーが乱立してしまうことが多い。したがって、ほとんどの場合、例外は大きなカテゴリー内に収めて、検索やファセットナビゲーションなどの見つけやすさをサポートするツールを追加することで、ユーザーを支援することをお勧めする。
参考文献
Roger Brown. 1958. How Shall a Thing Be Called? Psychological Review 65:14-21
George Lakoff. 1987. Women, Fire, and Dangerous Things: What Categories Reveal about the Mind, University of Chicago Press, London.
Elanor Rosch. 1975. Cognitive representations of semantic categories. Journal of Experimental Psychology: General, 104, 192-233
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。
{kind=link}