情報採餌:ユーザーがWebをどのように移動するかの理論
ユーザーはページを訪問するかどうかを決めるのに、情報を抽出するのに必要な労力に比べて、そのページで関連する情報をどのくらい見つけられそうかを考慮に入れる。
ユーザーはWebページをスクロールしてくれるだろうか。彼らはリンクをクリックするかをどのように決めるのか。彼らはどんなときにWebページを離れるのか。そして、どういうときに検索を好み、どういうときにブラウズをするのか。また、情報の検索をモバイルアプリでするのか、それともWebでするのかをどのように決めるのか。
Webユーザーの行動に関するこのような質問に回答を与えてくれるのが、情報採餌理論(information-foraging theory)だ。
この記事では、理論の概要を紹介し、それがWebデザインに与える影響のいくつかを検討する。
動物の採餌行動との対比
1990年代後半にPeter PirolliとStuart Cardにより、情報採餌はPARC(旧XEROX PARC)において開発された。この理論は、動物が餌を探し回る採餌方法についての動物行動理論から着想を得ている(だからこの名前になっている)。したがって、当然のことながら、動物の採餌と情報の採餌の理論は、以下の表に示すように用語を共有する。
| 動物の採餌 | 情報の採餌 | |||
|---|---|---|---|---|
 |
餌 | 目標 | 情報 |  |
 |
餌の供給源になりうるところが一箇所以上ある場所 | パッチ(訳注:割り当てられたエリア) | Webサイト(などの情報源) |  |
 |
餌を探す | 採餌 | 情報を検索する |  |
 |
そのパッチが餌を供給してくれる可能性があるかどうかについての動物の判断材料 | 匂い | その情報源候補がユーザーにどのくらい有望に見えるか |  |
 |
動物が空腹を満たすために検討する餌の種類すべて | 食餌 | ユーザーが情報ニーズを満たすために検討する情報源のすべて |  |
情報採餌とは
情報採餌は、ユーザーが情報ニーズを満たすためにWebでどのように移動するかの基盤をなす理論だ。基本的には、ユーザーが特定の情報を目標としている場合に、情報源の候補から抽出できる情報をその抽出にかかるコストに照らし合わせて評価して、以下の利益率が最大になる1つまたは複数の情報源の候補を選択することをいう:
利益率=情報価値/その情報の取得に関連するコスト
つまり、ユーザーはわからないことがある場合にどのWebページにアクセスするべきかを、(1)そのページが自分の疑問に回答を与えてくれる可能性がどのくらいあるか、さらに、(2)そのページにアクセスした場合に回答を得るのにどれくらいの時間がかかるか、に基づいて決定する。
(動物行動科学では、同様の最適化が動物の採餌に当てはまることが示されている。よって、この最適採餌理論がPirolli とCardのインスピレーションの源となったというわけだ。基本的に、動物は消費する以上のカロリーを取る必要がある。さもなければ、飢えて、子孫を残さずに最終的には死ぬことになるからだ。何世代にもわたり、動物は高度に最適化された採餌戦略を進化させてきたのである)。
平たく言うと、ページ上でなぜユーザーが無意識にスクロールしないのか、あるいは、すべてのリンクをクリックしたりしないのかは、情報採餌によって説明がつく。ユーザーは利益率を最大にしようとして、できるだけ短時間で多くの関連情報を取得しようとするからだ。おそらくスクロールやクリックをもっとすれば、ユーザーが獲得できる情報は増えるだろう。しかし、そうすると利益率が低下すると彼らは考えるのである。分母の増加(情報の取得に関連するインタラクションコスト)に比べて、分子(情報価値)の増加が少なすぎると思うからである。
利得を最大化する行動を常にとるほどユーザーは合理的なのか、と疑問に思うかもしれない。結局のところ、ユーザーが自分の利益に反する非合理的な行動を取る例は数え切れないほどある。しかし、実際のところ、人間の行動は、ノーベル賞受賞者Herbert Simonが言うところの限定合理性によってきちんと説明が可能である。利益を最大化し、コストを最小限に抑えようとして、ユーザーは選択する。しかし、その一方で、利得とコストを正確に見積もるのはたいへんである。その結果、彼らは満足化(satisficing)などの不完全なヒューリスティックスを利用して、最も有望そうな選択肢を選ぶのである。得られる数値はすべての場合に理論的な最適であるとは限らない。しかし、それでも、全体的に見れば、最高の利益率を目指す効果が認められるということだ。
具体的に言うと、(1)あるパッチに含まれる情報の量、さらに、(2)そのパッチから情報を抽出するのにどれくらい時間がかかるか、を事前にユーザーが知る術はない。ただし、彼らは、ある特定のタスクに対して、過去に実際にどれだけの時間を費やし、どれだけの関連コンテンツを得ることができたかはしっかりわかっている。そこで、次に見るべき情報源を選ぶのに、ある特定の情報源を調べようとすると利益率がどう変わるかを考えるのである。もちろん、こうした判断は完璧ではない。情報源が発する外的手がかりが根拠になっているにすぎないからだ。
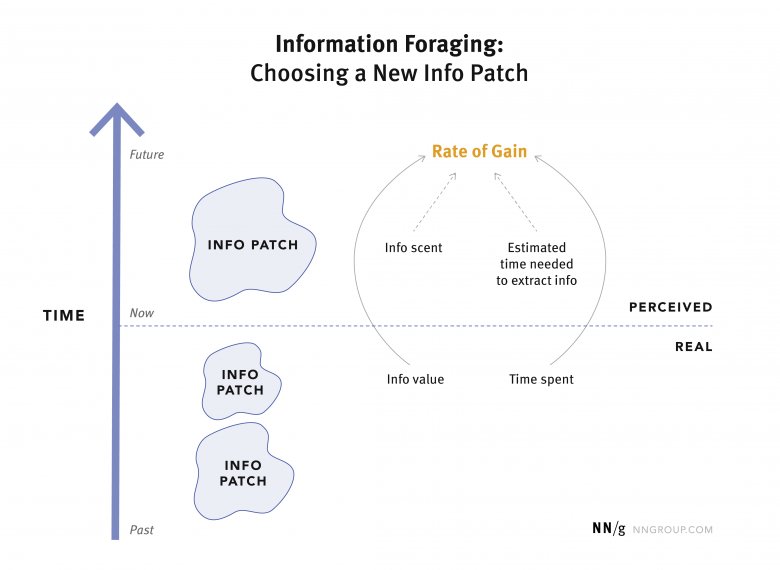
情報ニーズに合った情報を入手しようとする際、ユーザーは、多くの場合、複数の情報源、つまり、情報パッチ(Info patch)を検討する。どの時点においても、すでに訪問済みの全パッチからこれまでに得た実際の情報価値と、その情報を収集するために費やした実際の労力(時間)が彼らにはわかっている。そこで、ある新しいパッチを調べる価値があるかどうかを判断するために、彼らはそのパッチを選択した場合に、情報利得率(Rate of gain)がどのように変化するかを考える。この推定は、そのパッチの情報価値(Info value)についてパッチから受け取る手がかり、つまり情報の匂い(Info scent)と、その情報を抽出するために必要な知覚される労力(Estimated time needed to extract info)に基づいておこなわれる。だが、こうした推定が実際には間違っており、そのパッチに関連する実際の情報価値と労力が、ユーザーが知覚する情報価値(または情報の匂い)や労力とは異なる可能性もある。
情報の匂い
ユーザーはページを訪問する前に、ページから取得する情報の量をどのように推定するのだろうか。ここで、情報の匂いという概念が役に立つ。
動物は自然環境から感じ取れる(とりわけ)匂いに基づいて、どのパッチで採餌するかを決める。つまり、匂いという合図によって食べたいと思う餌があることを知ると、動物はその匂いをたどろうとする。
同様に、ユーザーはWebで情報を検索する際、そのWebページが自分の目標にどれだけ合っているかに基づいて、遭遇したWebページを判断する。したがって、各情報源は、必要な情報が含まれている可能性を採餌者に示す合図である、「匂い」を発しているということになる。
なお、動物採餌の世界で、動物によって食べる餌が違うように、匂いはユーザーが興味をもっている情報の種類に大きく依存していることに注意しよう。たとえば、肉食動物は血の匂いに引きつけられるかもしれないが、草食動物は血の匂いにはまったく関心がなく、熟した果実や新鮮な草の匂いのほうを好むだろう。同様に、同じ情報源でも、まさに見たいものがそこにあるということから、あるユーザーには情報の匂いは非常に強く感じられるかもしれないが、情報ニーズが異なる別のユーザーには情報の匂いがまったく感じられない可能性もある。
では、Webページの匂いを作り出すものとは何だろうか。ユーザーがそのページにたどり着いたときに、タイトルや画像、また、ファーストビュー内のすぐ目に入る情報から情報の匂いは発せられる。たとえば、あるユーザーが布巾を探していて、イチゴやビール、お菓子の写真が出ているサイトに到着すれば、単に匂いの方向性が彼女の求めているものとは違うということで、このページに彼女の必要なものがある可能性は低いと思うだろう。
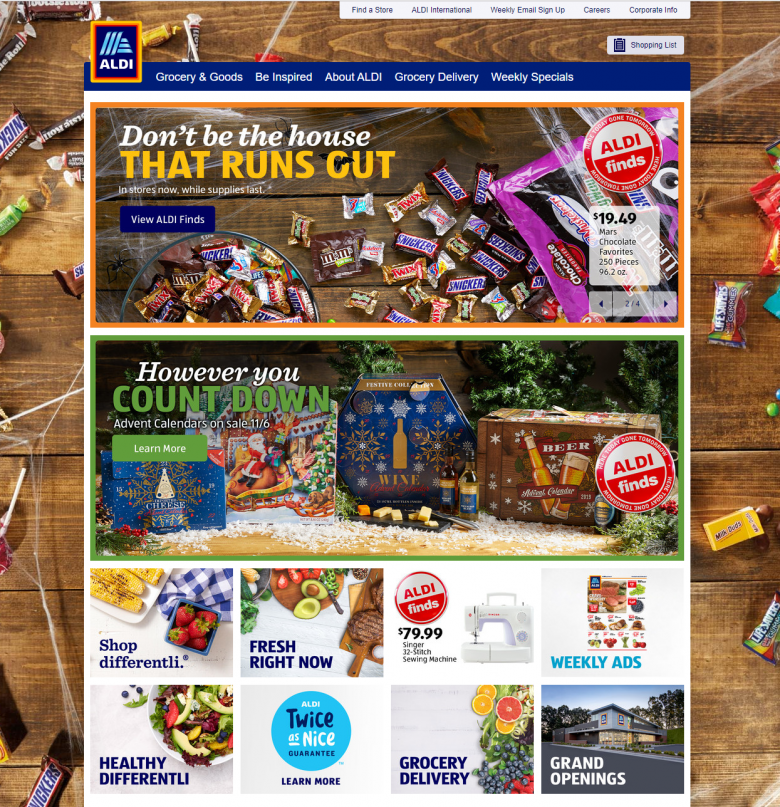
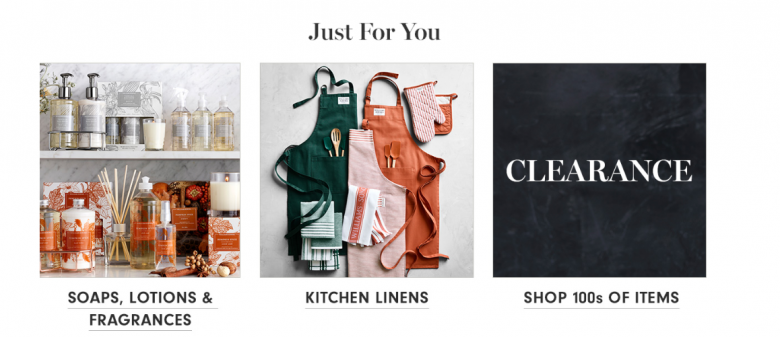
ユーザーがページへのリンクを見ているときに、リンク自体の言葉とそのリンクに関連づけられている画像のすべてから情報の匂いは発せられる。したがって、布巾を探しているこのユーザーは、「キッチンファブリック」(Kitchen linens)というリンクがエプロンやキッチン用手袋、布巾の画像のそばにあれば強く引きつけられるかもしれない。
情報ニーズに対処するコスト
上記の利益率の方程式には、情報価値と情報取得コストという2つの変数が含まれていたことを思い出してほしい。情報の取得に関連するコストには、(1)さまざまな情報源からの情報の抽出にかかる実際の時間と労力、および(2)(他の文書を調べることのメリットを諦め、該当の文書を選んだことから生じる)機会コスト、の2種類がある。
(有料のシステムでは、各文書の金銭的な価格という観点から3番目のコストがかかることになる。しかし、ほとんどのWebサイトは無料でアクセスできるため、この記事では金銭の支払いについてこれ以上論じない。重要なのは、たとえドル記号が付いてなかろうとも、ユーザーの時間と手間というのは実際にはコストであるということだ)。
機会コスト
ユーザーがあるWebページを調べようとするときは常に、それ以外のページを見る機会を失っていると考えることもできる。そのため、ユーザーがページに到達すると、即、要点を抽出しようとして、詳細情報を掘り下げない、というのは理にかなっている。スクロールダウンして、ページ上の単語を1つ1つ読み取るのは非生産的だからだ。つまり、この行動から得られる情報の利用価値は非常に小さい可能性が高い。それに対して、先に進みながら、浅く流し読みをしていくほうがはるかに役に立つことがわかっている。
時間コスト:パッチ間とパッチ内
時間は、ユーザーが必要とする情報の収集に必要な労力を反映する。
通常、WebまたはWebページで情報を調べるには、以下の2種類のユーザーアクションが必要である:
- パッチ間アクティビティ:情報源(つまり、パッチ)の収集。
- パッチ内アクティビティ:各パッチを調べてそこから情報を抽出。
たとえば、風邪の治療法を調べたければ、検索エンジンで検索をすることから始めるかもしれない。その検索結果ページには、情報源になる可能性のある一連のリンクが表示されるだろう。そして、この段階で、パッチ間で作業をおこない、後で調べる情報源を収集する。
検索結果が表示されたら、次に、最も有望そうなリンクをクリックして、関連情報を抽出するためにそのコンテンツに目を通すことになる。この段階で、個々のパッチ内で作業をして、各パッチを調べ、自分に関連する情報を抽出するということだ。
パッチ間とパッチ内のアクティビティの両方によって、情報のニーズを満たすための所要時間は決まる。さらに、この両者は多くの点でユーザーエクスペリエンスに影響をもたらす。そのため、ユーザーはパッチ間またはパッチ内で費やされる時間を最小限に抑える適応策を作成することがある。こうした適応策をエンリッチメントという。
エンリッチメント
パッチ間時間とパッチ内時間はどちらもエンリッチメントによって最小限に抑えることができる。
エンリッチメントとは、情報の採餌の有用性を最大化することを目的とする、ユーザーのインタラクションや行動、戦略のことである。これは、パッチ間またはパッチ内でおこなわれる。
エンリッチメントは、より効率的に情報採餌をするためにユーザーが利用できる追加ツールと考えるとよい。このツールは、ユーザーがすでに完全に自分のものにしているものの場合もあれば(学習した動作など)、その場で構築して特定のパッチに合わせて調整されるものもある(この場合、ユーザーはこのツールの作成に時間を費やす必要がある)。
行動のエンリッチメントとは、ユーザーがすでに獲得済みの、情報の効率的な抽出に役立つツールのことをいう。こうした行動は適応策として、時間の経過とともに進化してきていて、過去の多くの状況でうまくいくことが証明されたものである。
たとえば、Webとのさまざまなやり取りを通して、ユーザーはパッチの収集やパッチの情報価値の推定に費やす時間を最小限に抑える行動を考案してきた。その結果、ミレニアル世代は、コンテキストを切り替えるコストを回避するために、ページパーキングを利用して、採餌用の情報抽出と情報収集の要素を明確に区別している。あるいは、時間を節約するために、ユーザーはWeb検索結果をF字型に流し読みをすることで、すばやく情報の匂いを判断できるので、検索結果に関連するテキスト全部を読む必要がない。
パッチレベルでは、ユーザーは関連するコンテンツをすばやく見つけるために他の流し読みパターン(たとえば、レイヤーケーキ型)も考案している。また、彼らはバナーや右レール(右のカラム)を無視する傾向があるが、これもページに費やす時間に対する情報利得を最大化するための適応行動である。
インタラクションのエンリッチメントには、ユーザーのさらなる労力が必要である。情報採餌タスクの効率を最大化するために、ユーザーがその場で構築しなければならないツールだからだ。
たとえば、ユーザーは検索結果の関連度を高めようとして、自分のクエリを最もよく説明する特定のキーワードを考える。あるいは、検索フィルターをたくさん指定したりもする。こうした行動はどちらも、パッチ間のエンリッチメントといえる。
また、パッチ内では、ページ内検索の利用といった戦略を用いて、自分に関連するコンテンツをすばやく見つけることができる。
優れたユーザーエクスペリエンスはエンリッチメントを不要にする
エンリッチメントは、ユーザーにとって次の2つの理由でリスクを伴う。エンリッチメントによっては、ユーザーが追加のインタラクションコストを支払うか、より大きな認知負荷を負担しなければならない。さらには、そのエンリッチメント自体が実行中のタスクに適していない可能性がある。たとえば、F字型にWebページを流し読みするユーザーは、段落の先頭に表示されていない重要な概念を見逃す可能性がある。あるいは、初めて芝刈り機について検索する人は、検索するための関連キーワードを思いつけるほど、芝刈り機という分野についての知識がないかもしれない。
では、パッチ間とパッチ内の環境がユーザーの一歩先をいって、彼らのニーズに合わせて調整されているために、ユーザーが特別なエンリッチメントを作成する必要がない、と想像してみよう。つまり、こうした環境では、すでに情報の採餌の効率が最大化されている。これこそが優れたユーザーエクスペリエンスというものだ。
優れたユーザーエクスペリエンスには、ユーザーが最小限の時間で最大の関連情報を取得できるようにデザインされたWebページが必要なのである。
最適化の中にはすでに実施されているものもある。実際のところ、現在の検索エンジンは、洗練された方法で検索結果をランクづけしており、最も関連性の高い結果が最初に表示されるようになっている。そのユーザーがよくおこなう検索を利用して検索エンジンが結果をパーソナライズするため、ユーザーがクエリを絞り込むのに時間をかけなくても、高い確率で求める結果を得ることができる。なぜならば、検索エンジンが彼女のことを「わかっている」、あるいは、同様のクエリを実行するときにほとんどのユーザーが意図していることがそれだからだ。また、検索のオートサジェストでも、こうしたエンリッチメントについての検討時間を減らすことが可能である。
ページレベルでは、適切にデザインされたページに情報をどのようにレイアウトし、表示するかによって、そのページで最も重要な情報を示唆することができる。たとえば、デザイナーが箇条書きのリストや太字のキーワード、説明的な見出しなどの流し読みしやすい書式を利用することで、自分に関連する情報をユーザーが見つけやすくなる。
もちろん、難しいのは、ユーザーによって探している餌の種類が異なることだ。あるユーザーの目標とする情報が非常に具体的な特定の内容である場合、それは次のユーザーの目標とする情報とは異なるだろう。では、ページレイアウトとページが発する情報の匂いをどのように最適化すれば、すべてのユーザーとすべての目標に有効なのだろうか。
答えは、そういうことはしない、ということだ。やるべきは、ページやサイトが対処しなければならない最も重要なタスクに最適化することだ。そうすれば、そのタスクを実行することになる多くのユーザーに対応することができる。また、そうしておけば、そのページに無関係な、別のタスクを解決しようとしている多くのユーザーにも対処できるだろう。彼らはそのページをクリックする気にはならないはずだからである。
結論
ユーザーはWebで情報を探すとき、情報利得率を最大化しようとする。つまり、できるだけ多くの情報を最小限の時間で取得したいと考えている。そして、情報を探す時間を短縮するために、情報の匂いに基づいてページの情報価値を推定し、学習した行動やインタラクションなどのエンリッチメントを利用して、情報の採餌に必要なものをすばやく獲得できる可能性を高めようとするのである。
参考文献
P. Pirolli, S. Card. 1999. Information foraging. Psychological Review 106, pp. 643-675.
ダウンロード
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。