タクソノミーの基礎:
その定義とベストプラクティス、他のIA作業をどのように補完しているか
タクソノミーとは、目に見えるナビゲーションを補完するバックステージの構造のことである。タクソノミーは、秩序だったメタデータのルールを作成することで、一貫した情報検索をサポートする。
タクソノミー(taxonomy)とは何か、そしてなぜそれがUX実践者にとって重要なのか。UXカンファレンスの情報アーキテクチャコースで、タクソノミーとは何か、それをどのように構築するのか、情報アーキテクチャ(IA)作業という大きな流れの中でどのように位置づけられるのか、という質問を私はよく受ける。
タクソノミーとは、情報科学の専門家が統制語彙(controlled vocabularies/制限語彙)と呼ぶもので、記述的なメタデータをコンテンツに追加することで、コンテンツを効果的に検索できるようにするための、計画的・規定的な方法のことである。要するに、コンテンツを記述するための限定された用語一式を背後で定義しておく、ということだ。したがって、コンテンツ制作者は、新しいコンテンツに毎回その用語を付与する必要があり、この語彙をその場その場で増やしていくことはできないのである。
定義:タクソノミーとは許容可能な用語の閉じたリストのことで、用語は階層的に配置されていて、コンテンツについての記述や分類に用いられるものである。
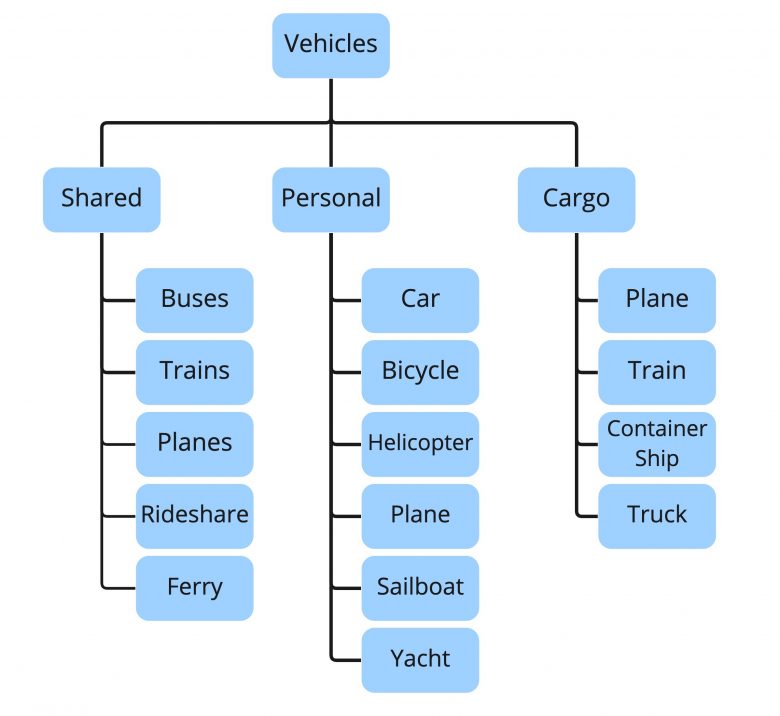
タクソノミーは、基本的には統制されたタグシステムで、各コンテンツにはタクソノミーの用語が付与されることになり、コンテンツ作成者が独自の用語を定義することはできない。そして、タクソノミーを用いてコンテンツにタグを付けるたびに、使用する用語と、その用語と他の用語との関係に関する基本ルールに従う必要がある。
注意してほしいのは、タクソノミーはユーザーが操作するナビゲーション構造とも、その基盤であるIA構造とも異なるということだ。この点については以下で詳しく説明する。
IAにおける4種類の構造化モデル
確かに、情報アーキテクチャはわかりにくい領域といえる。抽象的な構造化モデルの種類がいろいろあり、どれもよく似ているように見えるのに描き出すものはそれぞれ異なるからだ。以下が主な4つの構造化モデルである:
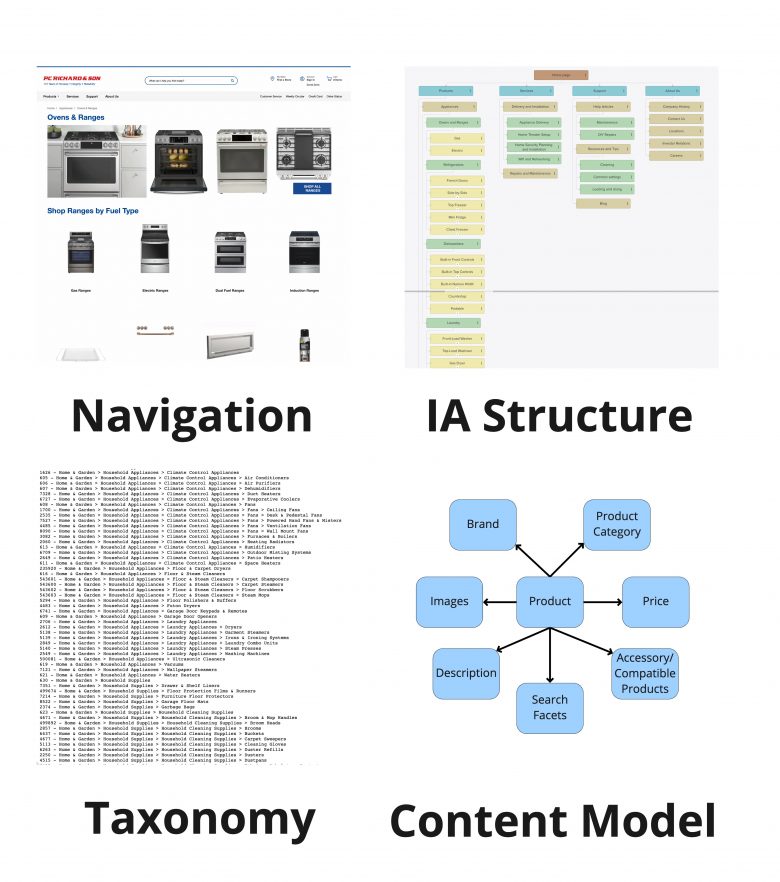
1. ナビゲーションとは、ユーザーが現在どのページや画面を見ていて、そこからどこに移動できるかを示す一連のUI要素(メニュー、リンク、パンくずリスト、アコーディオン)のことである。サービスデザイン用語では、ナビゲーションはフロントステージにあたる(すなわち、ユーザーから見える)。
2. IA構造(サイトマップと呼ばれることもある)は、サイトのすべての主要なノード(ページや画面など)と、それらの間の関係を示したマップのことである。IAはバックステージの一部であり、ユーザーに直接表示されるものではないが、デザインチームがナビゲーションをデザインしたり、コンテンツの移動先を決定したりする際に利用される。IAは、一般的には、ナビゲーションに類似しているが、はるかに範囲が広い。IAとはWebサイトにあるすべてのコンテンツの全体図であり、ユーザーが一度に見ることができる小さな部分ではないからだ。巨大なオフィスビルを思い浮かべてみるとよい。そこでは、看板や標示、エレベーターがナビゲーションを構成している(しかし、ビル全体を一度に見ることはできない)。それに対して、建築設計図はビルの基本構造全体を示すものであり、IAに相当する。
(情報アーキテクトとタクソノミー主義者の間では、IAツリー構造がタクソノミーにあたるかどうかがたびたび議論になる。IAツリー構造は非常に緩い形式のタクソノミーであると主張することもできるが、ここでは、IAツリー構造と、秩序だったメタデータタクソノミーとは区別して考えることにする。なお、これがメタな分類として皮肉な回答になっていることは認識している!)
3. タクソノミー(などの統制語彙)は、それぞれのコンテンツ(ページ、テキスト、データ、製品、ヘルプ記事、ファイルなど)について記述し、類似した他のコンテンツと関連づけるために用いられるメタデータである。
IA構造が、コンテンツがどのように構成されているかのマップであるのに対し、タクソノミーは、コンテンツについて記述するために用いる概念と、そうしたすべての概念が互いにどのように関連しているかを示すマップである。タクソノミーは、多くの場合、IA構造やナビゲーションとは大きく異なっていて、通常、その2つよりも広範で、より技術的なものである。
タクソノミー自体はユーザーには表示されないため(とはいえ、ナビゲーション、検索サジェスト、絞り込みとして、トピックやタグの一部が表示されることはある)、そこでは非常に論理的で精密な分類作業に没頭することができる。我々は、通常、タクソノミーでは論理的な正確さにこだわる。一方、目に見えるナビゲーション構造では、ユーザーのメンタルモデルに忠実なやり方で物事をグループ化することを重視する。
4. コンテンツ(またはデータ)モデルもまた、バックステージに属していて、さまざまな種類のコンテンツ、それらに含まれる情報、他の種類のコンテンツとのリンク方法、それらに適用されるメタデータなどを記述するために用いられる。
たとえば、このNN/gのコラムの記事には、著者(著者のプロフィールページへリンクされている)、トピック(同じトピックの他のコンテンツへ、存在する場合はそのトピック全体の概要ページへリンクされている)などがある。
なぜタクソノミーを作成し、UX担当者が関与すべきなのか
タクソノミーは、純粋に物事を分類することが好きだからという理由で作り出されたわけではない(私のように分類することが無条件に大好きなUX担当者もいるが)。タクソノミーを使うと、特定の概念に関連するすべてのコンテンツを効果的に検索できるからだ。タクソノミーの典型的な利用方法は以下である:
- コンテンツ同士の関連づけ。関連コンテンツウィジェットは、多くの場合、同じタクソノミーカテゴリー内にあるコンテンツを、たとえそれが別のナビゲーションカテゴリーにある場合でも表示する。たとえば、NN/gサイトでこの記事の下に表示されている関連記事は、トピックの内部タクソノミーから取得したもので、サイト上部に表示されているより上位レベルのトピックよりもはるかに詳細で具体的だ(たとえば、この記事は「情報アーキテクチャ」というトピックに属しているが、バックステージでは「情報アーキテクチャ>メタデータ>統制語彙>タクソノミー」というより詳細な分類を用いている)。
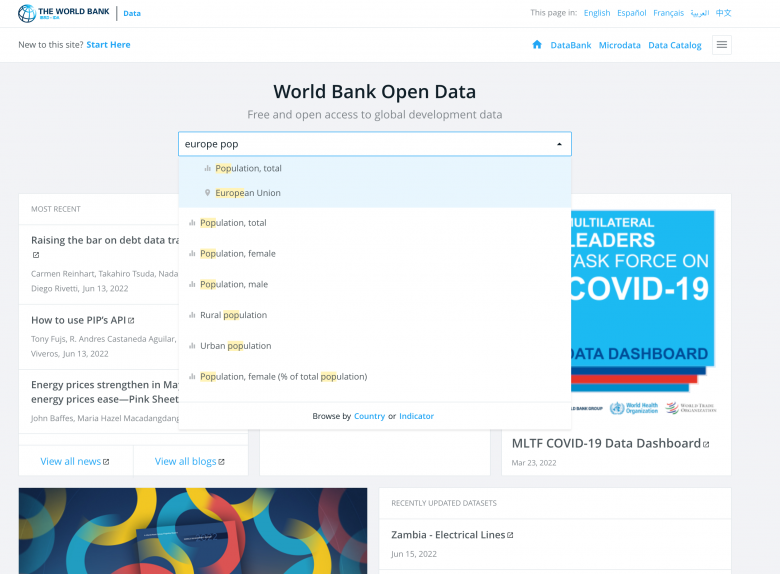
- ファセットナビゲーション。ファセットとは、ユーザーが複数のフィルターを同時に適用できるようにするもので、これはファセット化されたタクソノミーをベースにしている。ファセットを利用すると、ユーザーは欲しい情報をかなりのところまで絞り込めるようになり、深いナビゲーションツリーをうんざりするほどブラウズせずに済む。
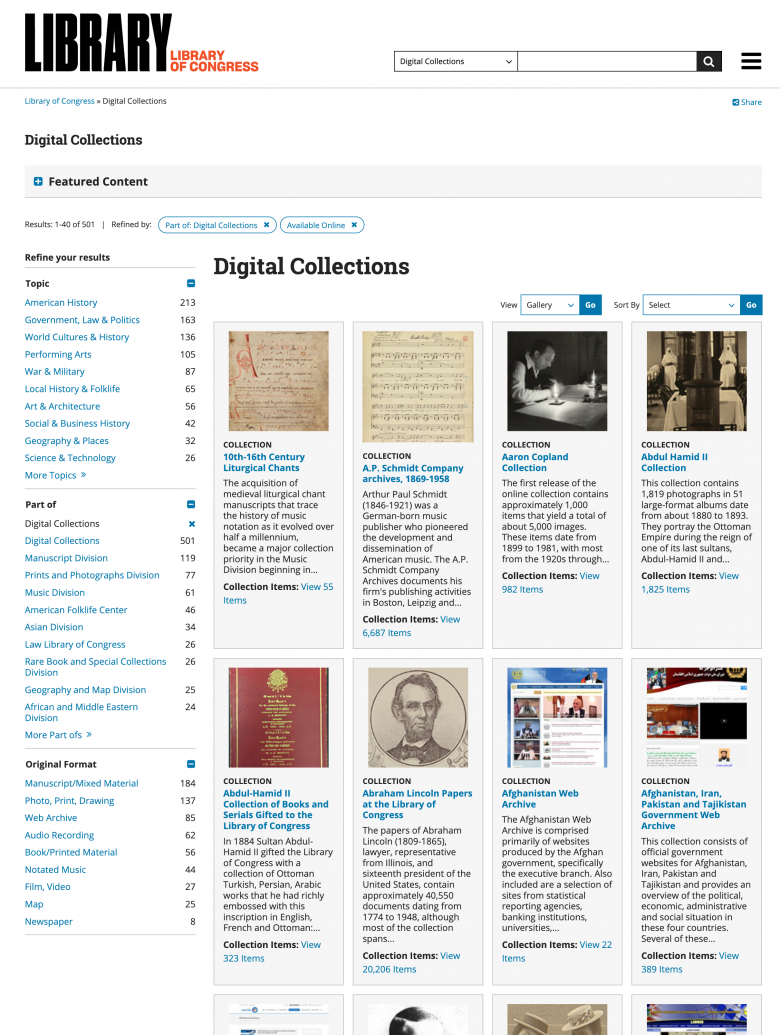
- 検索サジェストと絞り込み。ユーザーが検索キーワードを入力しているとき、システムはタクソノミーを参照して、関連する用語(ユーザーが入力したものとは異なるもの)から結果を表示する。また、カテゴリーを表示して、ユーザーの検索の範囲を広げることもできる。
その他の種類の統制語彙:シソーラスとオントロジー
また、タクソノミー、シソーラス、オントロジー、ナレッジグラフも混同されることが多い。これらはどれも、分類に利用されるメタデータの一種で、ノードが概念、エッジがこれらの概念間のさまざまな種類の関係を示すグラフとして表示可能である。
タクソノミーは、こうした構造体の中で最もシンプルなものだ。タクソノミーには、階層型とファセット型があり、ファセット型のタクソノミーは、複数の階層型タクソノミーから成っていて、こうしたタクソノミー同士で連携し、同じリソースのさまざまな側面を記述する。タクソノミーでは、概念間の親子関係が軸になり、タクソノミーを深く掘り下げるほど、概念はより具体的になる(より大きな全体の一部になることもある)。
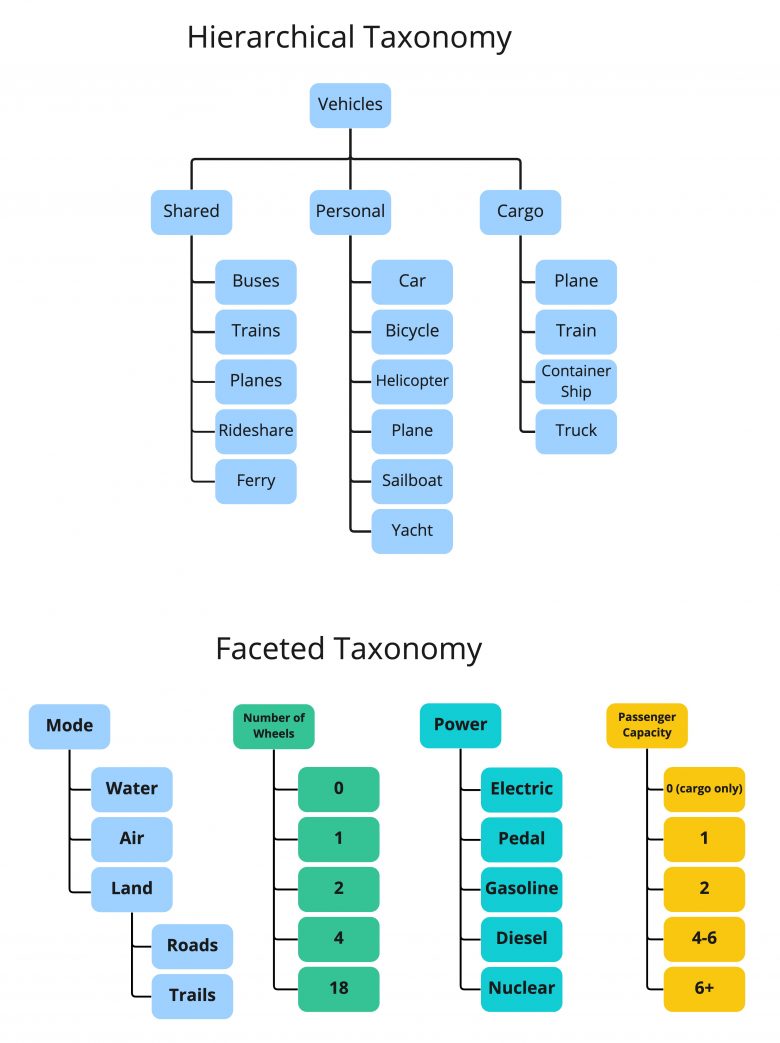
シソーラス(thesaurus)(紛らわしいが、辞書のシソーラス(訳注:類語辞典)のことではない)は、概念間の親子関係だけでなく、連想関係(同義語ではないが概念的に関連のある「関連用語」)と等価関係(同義語で、1つは公式の優先語、残りは非優先語)を含むデータ構造である。シソーラスを使うと、同義語と一貫性をコントロールできるので、この形式の統制語彙は徹底的な情報検索にとって非常に重要である。
たとえば、会社のイントラネットに「RFP」(:提案依頼書)、「提案」、「作業明細書」、「ピッチ」(:短時間で行う提案)というタグがあり、普段、どれもほとんど区別しないで使われているとする。その場合、これらのタグの1つ1つはそれぞれ関連するコンテンツの一部にしか関連づけられていないため、こうした用語のうちの1つだけを検索すると、不完全な検索結果しか得られないことになる。しかし、シソーラスは、こうした概念のすべてを関連語や同義語として(優先語として選択された用語と)関連づける。したがって、このケースでは、我々は「提案」と「ピッチ」を等価関係にして、「提案」を優先語にするだろう。そして、この両者はどちらも、「RFP」と「作業明細書」と連想関係になると考えられる。正確には同義語ではないが、概念的には確実に関連があるからだ。(注:デジタル製品用に作成された「タクソノミー」のほとんどは、実際にはシソーラスである。タクソノミーを管理するためのソフトウェアは、通常、優先語や関連用語などのシソーラス機能を備えているからだ)。
オントロジー(ontology)は、こうしたメタデータ構造の中で最も柔軟で複雑なものであり、複雑な技術分野でのナレッジマップの作成によく利用される。オントロジーは、概念を意味的に結びつける(親子関係や連想関係、等価関係を超えた)さまざまな重要な関係をサポートする。
たとえば、我々の多くが学校で覚える必要のあったリンネの生物分類法では、ホッキョクグマはクマ科の特定の種類で、食肉目の特定種である、という具合だ。ここでの概念同士の関係は親子関係(またはクラス包含関係)という1種類に限定されているが、オントロジーでは他の種類の概念的なつながりもマップ化することができる。たとえば、ホッキョクグマはクマの一種であるだけでなく、その生息地は極地であり、保全状況は絶滅危惧であるなど。このようにある知識分野について形式化できる特性同士の関係を構築することによって、親子関係以外のさまざまな側面を形式的な構造に取り込み、それをデータベースの作成に利用することができる。
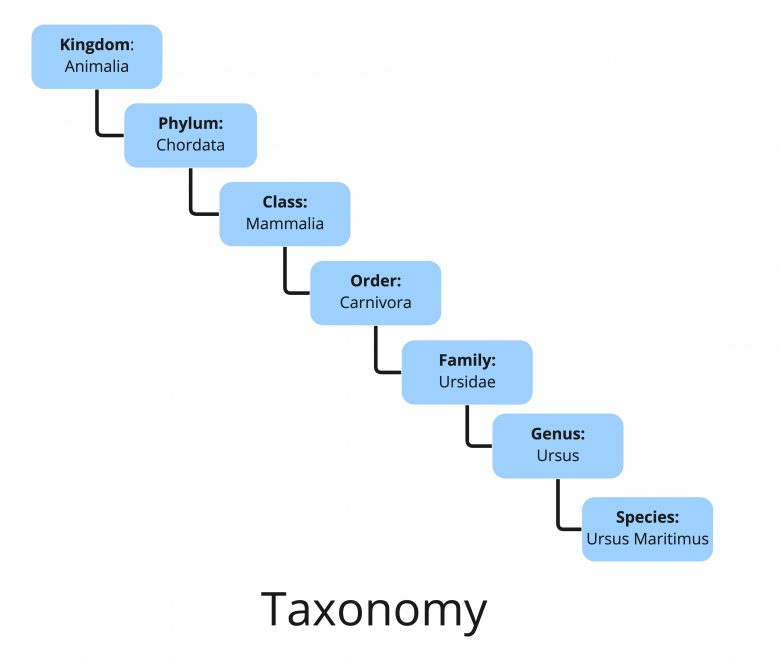
(界:動物界、門:脊索動物門、綱:哺乳綱、目:食肉目、科:クマ科、属:クマ属、種:ホッキョクグマ)
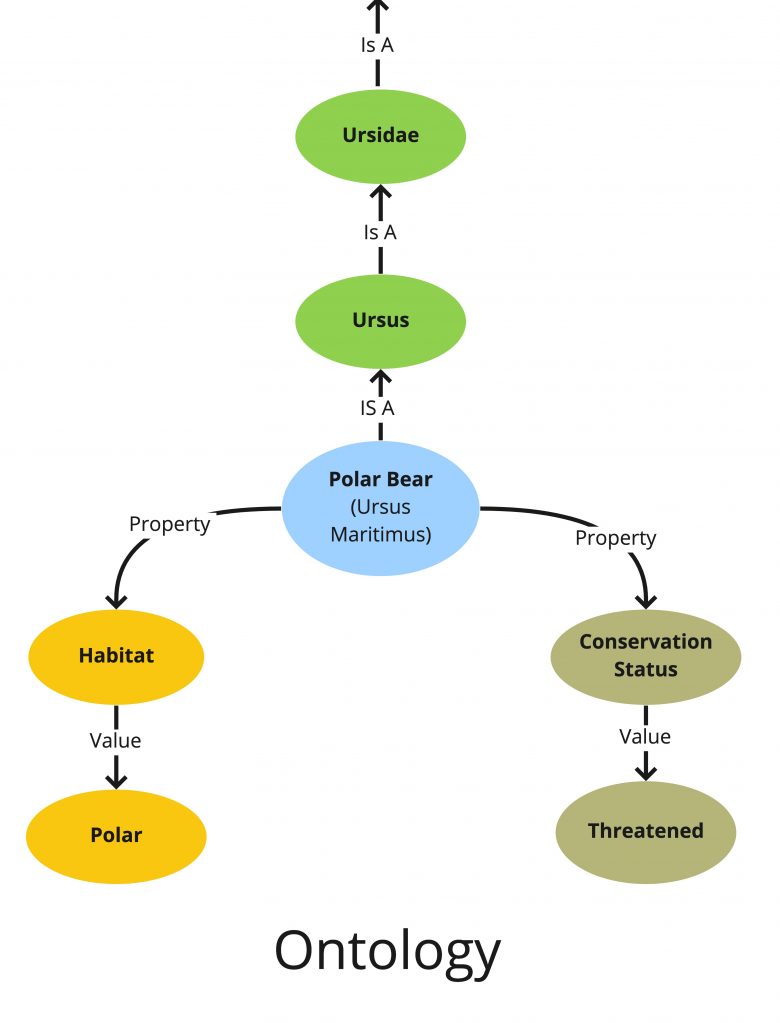
オントロジーは柔軟なので、概念間のさまざまな関係の表現が可能であり、情報を詳細かつ多面的に分類することができる。
オントロジーは大規模で複雑なプロジェクトであり、特定の知識領域を記述するために用いられるのが一般的だ。オントロジーの構築は、多くの場合、オントロジーの専門家、タクソノミーの専門家、ソフトウェア開発者、ドメインエキスパートによるチームによって行われるため、1人のUX担当者が単独で引き受けるような種類のものではない。しかしながら、オントロジーを知っていて、タクソノミーとどのように関連しているかを把握しておくことは重要だ。特に科学分野やセマンティックWebプロジェクトに携わっていると、オントロジーというのは目にする機会が多いので、オントロジーが何かということを理解しておくのはUX実践者にとって有益である。
タクソノミーの構築
タクソノミーをゼロから構築するのはかなり複雑なプロセスであり、その方法の詳細はこの記事の範囲外であるが、プロジェクトの種類に関係なく、その進め方にはいくつか共通のテーマがある。タクソノミーは数年がかりのプロジェクトではなく、小さな規模から始めて構わない。単にコンテンツに一貫して割り当てる小さなトピックの集合を背後で持つだけでもいいのだ!
- 何はさておき、コンテンツの棚卸しと監査をする。どんなものを構造化するのかを知らずに、それを構造化することはできない。
- 最初に、自分たちの業界やドメインに適した標準的なタクソノミーがあるかどうか確認する。既存のタクソノミーがあれば、かなり有利なスタートが切れるだろう。自社固有の事情に合わせて修正する必要があるかもしれないが、たくさんの労力を節約できると思われるからだ。既存のタクソノミーは、必要なコストがさまざまであることに注意しよう。無料でオープンソースのものもあれば、かなり費用のかかるライセンスが必要なものもある。まずは、BARTOC.orgで、どんなものがあるかを調べてみるとよい。
- タクソノミーを構築する際に中心になる概念を特定する。こうした概念は、コンテンツ自体や既存のメタデータ(コンテンツ管理システムのキーワードやトピックなど)、対象分野の専門家との議論、社内の主要なビジネス用語から見つけることができる。また、こうした概念は、インタビューやユーザビリティテスト、検索ログなど、既存のユーザーデータからも抽出するようにし、ユーザーのためにならないタクソノミーの分岐を構築しないようにする必要がある。
- 特定した主要な概念ごとに、他の関連する類似した概念や単語に関する情報と、この概念のソース(WebサイトのURLなど)を把握する。
- 選んだ用語候補を評価する。ユーザーのニーズとの関連性を調べて、「特異点」、つまり、その概念以外に関連語がない用語や、トピックをほんの少ししかカバーしていない用語は入れないようにしよう。1つのコンテンツにしか関連がない概念を入れるのは、努力が無駄になる可能性があるからだ。
- 各概念の優先語と非優先語のバリエーションを決める。タクソノミーはユーザーに全体が直接表示されるわけではないので、ナビゲーションで使いそうなものよりも社内のビジネス用語を使うと、ここでの選択の幅が少し広がる。とはいえ、トピックのリンクや検索サジェストに表示させる用語もあるので、ユーザーにとって情報の匂いが強い語を優先語にすることをおすすめする。ベストプラクティスは、ユーザーがよく知っている用語を優先語にし、社内ビジネス用語やより専門的な用語を非優先語としてリンクすることである。
- 概念間の関係を構築する。階層型のタクソノミーを採用するということは、ツリーの分岐を定義し、概念間の親子関係を決定するということだ。タクソノミー構築の作業の大部分はここで発生することになる。階層内の各階層の粒度を1つ1つ決定していく必要があるからだ。また、この時点で、同義語ではない関連概念を特定し、それらを関連用語という関係で結びつけることも行う(したがって、正確に言うと、ここでシソーラスも構築することになる)。
- ステークホルダー、社内の対象分野の専門家、コンテンツストラテジストとともにタクソノミーを見直し、修正する。このプロセスでは反復的な改良がおこなわれる可能性があるが、そこでの話し合いに(特に優先語の選択について)ユーザーの視点をもたらすのがUX担当者の役割である。
- タクソノミーをコンテンツに適用する。扱っているコンテンツの量によっては、これはかなりの労力を要する作業で、タクソノミーの使い方(ある用語と別の用語の使い分け方など)についてタグを付ける担当者をトレーニングする必要がある。もちろん、自動的に分類してくれるAIツールもあるが、そうしたツールにも誤りはあるので、手作業による微調整と編集が必要になることを想定しておこう。
- 継続的な管理とメンテナンスの計画を立てておく。タクソノミーが長期間、有用であるかどうかは、定期的に見直しを実施し、用語を追加したり、言い方を変えたり、統合、削除すること、さらに、コンテンツのタグづけの例を無作為に抽出して、タクソノミーが適切に用いられているかどうかの確認を行っていくことにかかっている。
要約
タクソノミーは、デジタル製品において、コンテンツ同士の関係を構築する強力な方法であり、ユーザー向けのナビゲーションシステムが取り残す可能性のあるギャップを埋めてくれる、表示されることのないバックステージの構造化システムである。タクソノミーは、適切に定義し管理することで、検索サジェストや検索後の絞り込み、ファセットナビゲーション、関連コンテンツの自動リンクなどをより効果的にサポートすることができる。
資料
Dean Allemang, James Hendler. 2011. Semantic Web for the Working Ontologist (2nd. Ed.). Morgan Kaufman, Waltham, MA.
Heather Hedden. 2016. The Accidental Taxonomist (2nd Ed.). Information Today, Medford, NJ.
International Organization for Standardization. (2011) Information and documentation — Thesauri and interoperability with other vocabularies — Part 1: Thesauri for information retrieval (ISO Standard No. 25964-1:2011) Retrieved from https://www.iso.org/standard/53657.html
Mary Whittaker and Kathryn Breininger. 2008. Taxonomy Development for Knowledge Management. In World Library and Information Congress: 74th Ifla General Conference and Council, 10-14 August 2008, Québec, Canada http://www.ifla.org/IV/ifla74/index.htm
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。