
音声ファーストはインタラクションの未来か
画面もあるが音声を第一の入力手段として用いるデバイスは、ユーザーエクスペリエンスをさらに統合された、有益で全体的なものにする方法を示してくれる。
音声ベースと画面ベースのインタラクションは、2方向から1つに収束しつつある:
- 画面ファーストのデバイス(スマートフォンやタブレット、テレビなど)は、音声制御システムの付加によって強化されてきている。
- 音声ファーストのデバイス(スマートスピーカーなど)は、Echo Showのように画面を付けることで強化されてきている(他のブランドからも同様の製品がすぐに発売されるのは間違いないだろう)。
SFの描写にはよくあるが、音声が文字によるコミュニケーションに完全に取って代わるとは思わないほうがよい。しかし、人と機械の標準的なコミュニケーションが急速に拡大し、文字と音声の両方によるインタラクションがそこに含まれるようになってきているのは明らかだ。現在のところ、音声インタラクションは個人や家で主に利用されているが、こうしたインタラクションにユーザーが慣れていくにつれて、ビジネスや商用での利用も期待されるようになるだろう。(会議室のプロジェクターや電話会議のメニューに苦労したことのある人は、「画面を出して」とか「会議を始める」と言うだけで設定が済むことを想像してみるとよい)。
真に統合された音声画面システムは、広範なタスクのユーザーエクスペリエンスを変化させる。その際には、音声と画面それぞれのインタラクション形式の以下の強みを活かすことになる:
- 音声は効率的な入力様式である。ユーザーが自分の言葉で、システムにすぐコマンドを出すことができるからだ。ハンズフリーコントロールは、ユーザーがマルチタスクをおこなうことを可能にする。さらに、自然言語を効果的に処理することで、少なくとも、慣れているタスクやコマンドがわかっている場合には、複雑なナビゲーションメニューが不要になる。
- 画面は効率的な出力様式である。一度に大量の情報をシステムが表示できるようになり、ユーザーの記憶への負荷が減るからだ。目で見て流し読みをするほうが、音声出力では避けられない、シーケンシャルに情報にアクセスする場合よりも速い。また、システムの状態を効率的に伝えられるし、可能なコマンドを示すために視覚的なシグニファイアを提供して、「実行におけるへだたり」に橋をかけることもできる。
論理的には、この2つの様式を1つのシステムに統合すれば、間違いなくうまくいくように思える。しかし、まったく異なる2つのインタラクションモードの統合がデザイン上の課題となり、音声と画面の両方の利点を単一のシステムで完全に実現するということは今のところできていない。
画面ファーストのインタラクションの限界
最近まで、画面と音声制御が組み込まれているデバイスのほとんどは画面ファーストだった。たとえば、音声制御システム付きのスマートフォンには、SiriやGoogle Assistantのような音声エージェント形式のグラフィカルユーザーインタフェースが前もって搭載されている。
こうした画面ファーストのシステムによる音声認識や言語処理は見事なものである。しかし、全体的なユーザーエクスペリエンスはかなりバラバラのままだ。音声エージェントとタッチスクリーンのアプリケーションの機能が基本的に切り離されているからである。
機能の欠如
音声エージェントはタスクの最初のステップを開始するだけで、以後のステップで、ユーザーがタッチ形式のインタラクションに移行しなければならなくなることは多い。たとえば、Siriは音声コマンドに応じて、Web検索問い合わせを実行したり、Apple Newsアプリを開いてくれる。しかし、ユーザーはその後、画面をタップして、検索結果を選択したり、ニュースの記事にアクセスする必要がある。Google Assistantでも、検索で最初のステップより先に進むためには画面への入力が必要であることが多い。
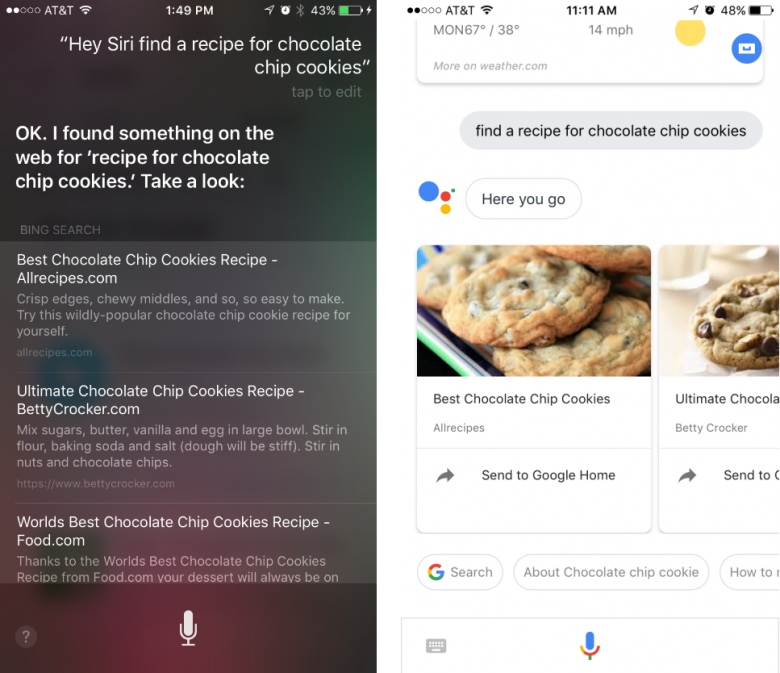
「音声モード」での画面スペースの使い方が不十分
多段階の音声入力をサポートしているようなタスクの場合でも、Siriの画面デザインはGUI版とはまったく異なっており、利用可能な画面スペースがうまく使えていないことが多い。たとえば、Siriはテキストメッセージを読み上げて、返信を送ることができる。しかし、テキストメッセージを読み上げているときには、画面全体が暗くなり、メッセージの送信者の名前だけが現れる。つまり、メッセージの実際の内容が表示されることはない。同様に、返信のときに、GUIのメッセージアプリケーションがするように、返答中のメッセージのテキストを表示することもない。こうした制約は、ユーザーが利用できる情報を不必要に制限するものだ。実際、音声モードはメッセージの履歴以上のことも表示できるはずだからだ。このモードではキーボードを表示する必要がないからである。
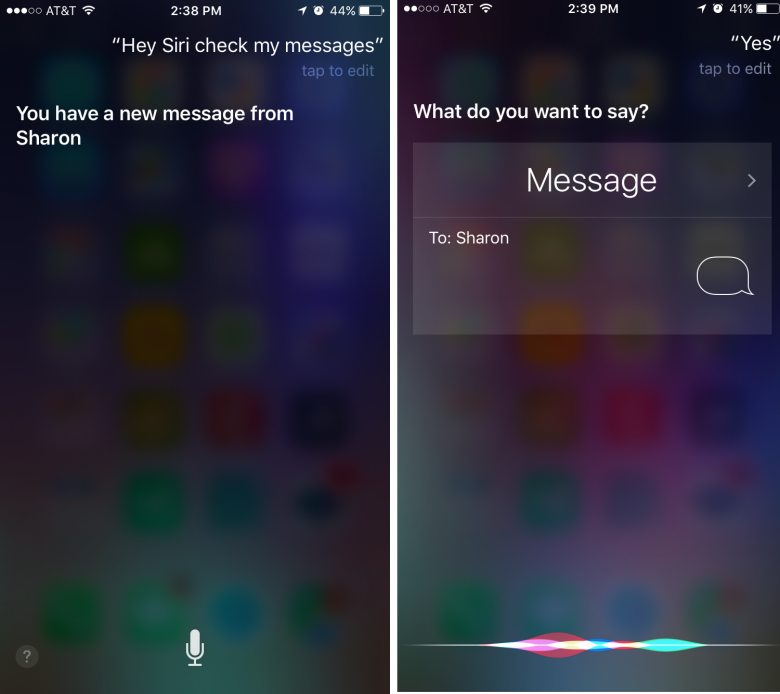
アフォーダンスの欠如
また、Siriのミニマリズム的な音声エージェント画面では、グラフィカルユーザーインタフェースに注意深く組み込まれてきた視覚的アフォーダンスがほとんど省略されている。たとえば、送信前にテキストメッセージの編集ができることをユーザーに知らせるアフォーダンスもない。(Google Assistantのほうがはるかにアフォーダンスがある。タスクの結果のすぐ下にコマンドが毎回サジェストされるし、過去のタスクを再訪問できるフィードもあるからだ)。
音声のみのインタラクション
音声インタラクションに対する根本的に異なったアプローチが、AmazonのEchoやGoogle Homeのようなスマートスピーカーの登場により出現した。こうしたデバイスには、視覚的なディスプレイがまったくないので、普段の利用では、入力も、(数個のライトが点滅することを除けば)出力も、音声に依存することになる。ほどほどの距離での音声認識の精度が大きく向上したことにより、スマートスピーカーでは、真にハンズフリーの操作ができるようになった。その結果、柔軟性と効率が向上し、音声対応のスマートフォンをすでに所有しているユーザーにとっても、魅力的なデバイスとなっている。
しかし、画面がないのはこうしたスピーカーにとって非常に大きな制約である。利用可能なコマンドをユーザーに知らせる手がかりとして、聴覚的な合図しか利用できないし、非常にシンプルなタスク以外は、アウトプットの読み上げが冗長なものになるからだ。たとえば、料理中に音声コマンドでタイマーをセットできるというのはすばらしいことだが、あと何分残っているかを聞かなければならない場合はそうでもない。また、天気予報の確認はユーザーにとっては記憶のテストになってしまう。画面をひと目見て確認する代わりに、一週間分の情報を連続して聞き取り、理解しようとしなければならないからである。
音声ファーストのインタラクション
スマートスピーカーは成功したが、その出力は音声のみに制限されていてじれったい、ということから、最近生まれた新しい製品がEcho Showだ。これはEchoの基本型であるスマートスピーカーに表示画面を追加したものである。この画面によって、元のEchoの機能が大幅に拡充され、天気のチェックやタイマーの監視のようなタスクがずっと楽になった。しかし、スマートフォンやタブレットでは昔から実行可能だった、基本的機能のパフォーマンスに関するEcho Showの能力は、(Amazon自身のはるかに安価なFire 7タブレットのような)完全なGUIをもつ画面ファーストのデバイスに比べると、はるかに劣るものだ。たとえば、(いまだに)Webサイトの閲覧もレビューの表示も自分のAmazonのショッピングカートの中身を表示することもできないからである。
Echo Showが 「実際に」提供するのは、これまでとは根本的に異なるインタラクション形式である。それは「音声ファースト」と言われるもので、音声を二次的な制限モードに追いやるのではなく、ほぼ音声入力のみに依存するやり方である。
音声ファーストのインタラクションとは、ユーザーの入力を主に音声コマンド経由で受け取るシステムのことで、密接に統合された画面ディスプレイによって音声出力を補完することもある。
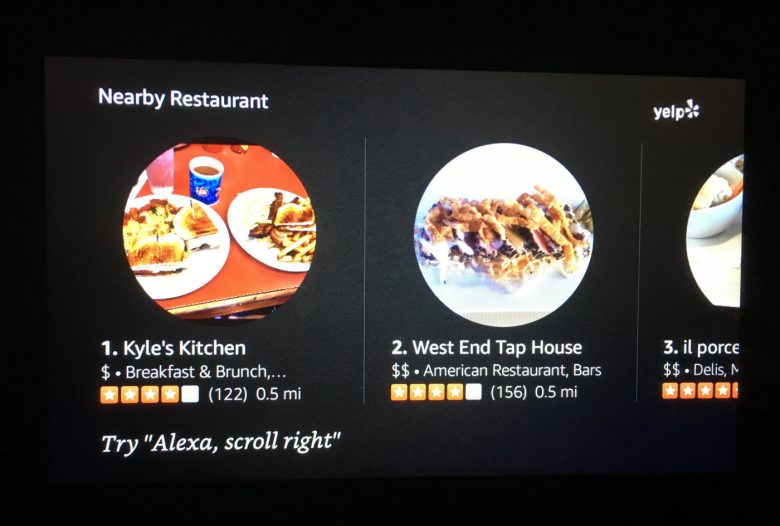
Echo Showは技術的にはタッチスクリーンだが、ボタンやメニューをたまにしか提供しない。(タッチキーボードはワイヤレスネットワークのパスワードを入れられるように仕方なく表示されるが、入力が終わると、速やかに消え去り、二度と表示されることはない)。ユーザーにタップやスワイプを促す代わりに、Echo Showでは、「『Alexa、右にスクロールして』と言ってみよう」のような、音声コマンドのサジェストが頻繁に表示される。
音声と画面の出力の徹底的な統合
基本的には、音声ファーストとは、既存のグラフィカルユーザーインタフェースに音声コマンドを統合するという課題に対する新しいアプローチといえる。まず、(音声のみの最初のEchoのように)GUIを完全に削除し、その後、画面を再導入して、全体的なシステムの一部として、視覚情報を少しずつ組み込んでいくというものだからだ。
人間とパーソナルデバイスの間の音声インタラクションは、新しい根本的に異なるタイプのコミュニケーションだ。つまり、ユーザーにとってもデザイナーにとっても、外国語のようなものである。外国語がその言語に浸ることで最も楽に身につくように、この様式だけに的を絞った環境にすることで、音声インタラクションの革新や採用も大きく進むだろう。
音声ファーストアプローチがきっかけになった興味深いイノベーションの例は、Echo Showのインタフェースですでにいくつか見ることができる:
- 検索結果に連番を振る。これはWeb検索が始まった初期の頃によく見られた慣例の1つだが、リストで表示するようになってからは不要になったため、その後長い間、おこなわれていなかった。音声ファーストのデバイスでは、こうした数字は、効果的な言語によるそのアイテム固有の「取っかかり」を提供するという重要な役割を果たしており、それによってユーザーがアイテムを効率的に選べるようになっている。
- サジェストするコマンドをランダムに表示する(たとえば、「『Alexa、Al Greenをかけて』と言ってみよう」や「『Alexa、好きな言葉は何?』と言ってみよう」など)。このテクニックは、Siri (「たとえばこのように尋ねてください」)やGoogle Assistant (「探す」)で使われている手法に類似したものだが、教育用のエリア内だけでなく、ホーム画面やさまざまな検索結果画面、音楽プレーヤー画面の一番下にもこうしたヒントが表示されるところが違う。(このように、見ているものの周囲にヒントが出てきて教えてくれるという仕組みによって、新規ユーザーを自然とデバイスに関与させられるのは間違いない。しかし、ランダムにコンテンツが出るというのは、経験豊富なユーザーにとっては、そのヒントに興味が持てず、うっとうしい場合も多い。このサジェストは消すことができないからである)。
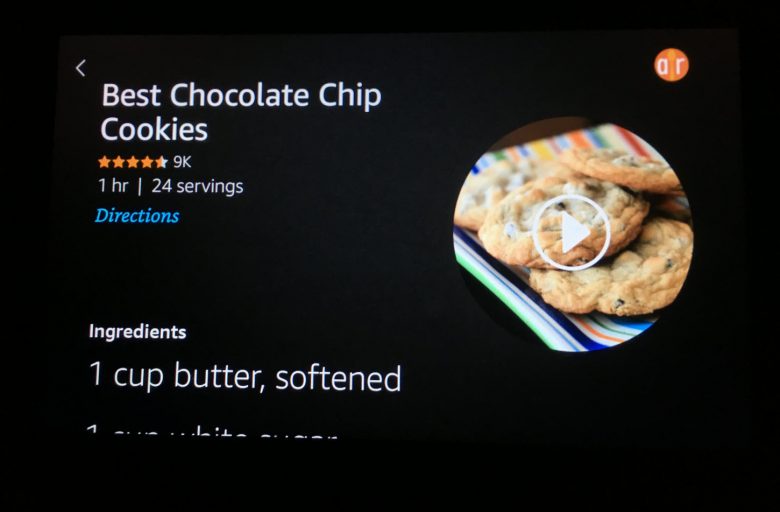
- リッチでインタラクティブなコンテンツをリアルに表示する。これは伝統的なWebやモバイルのGUIでは当たり前のことだが、これまでの画面ファーストの音声インタフェースではできていなかった。たとえば、Echo Showでのレシピの検索結果には、詳細画面もあり、材料や作り方、デモ動画が表示される。そして、そのすべてが音声コマンド経由でアクセス可能である。
音声ファーストは長期的なソリューションか
メニューやボタンなどの伝統的なGUI要素の削除は、音声インタラクションインタフェースを学ぶための第一歩としては必要なことなのかもしれない。しかし、(大型の画面の利用時にも、グローバルナビゲーションを非表示にするなどのまずいアイデアを生み出してしまった)「モバイルファースト」ブームのときと同じく、音声ファーストも万能ではない。
結局のところ、「純粋な」音声インタラクションという名のもとに、画面の機能に意図的にハンディキャップをつければ、デバイスの有用性が制限されるし、ユーザーの認知負荷も不満も増す。もともと視覚ディスプレイというのは、音声だけの出力よりも効率的に大量の情報にアクセスしてもらうための方法だからだ。
たとえば、音声ファーストということはつまり、Echo Show(=表示する)という名前にもかかわらず、このデバイスではリクエストしたものが何でも実際に「表示される」わけではない、ということだ。実際、Echo Showでは、インストールされたアプリケーション、つまり、スキル(Amazonではアプリケーションをこう呼んでいる)のすべてが載っているメニューといった、デバイスの基本的な情報を見ることもできないからだ。
Alexaのライブラリーには現時点で15,000以上のスキルがあるが、その多くはそのスキルの名前を言うことでしかアクセスできない。だが、仮に数十個しかスキルをインストールしていなかったとしても、どうやったらインストールしたスキルそれぞれの正確な名前を思い出すことができるというのか。パーソナライズされたサジェストや自然言語処理によって、アプリケーションのメニューを調べる必要性を減らすことはできる。しかし、音声エージェントが人の心を読めない限りは、どんな場合にもユーザーが興味を持ちそうな事柄を全部サジェストする、というのはとうてい不可能だろう。
音声ファーストにデザインすることで、音声インタラクション自体は大幅に向上するかもしれない。しかし、長い目で見ると、音声ファーストのインタラクションのために、視覚的なメニューを一方的に禁止するというのは、片手を後ろで縛った状態で戦いを始めるようなものである。また、全体的でインテリジェントな音声と画面のインタフェースという迫りくる複雑さに対峙するにあたり、UXデザイナーはあらゆるツールを必要としているといっていいだろう。
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。

