音声対話のUX:
すばらしき新世界…だが、変わらない部分もある
音声対話はグラフィカルユーザーインタフェースとはかなり異なるものだが、伝統的なユーザビリティ原則がそこでのユーザーエクスペリエンスの質に決定的な役割を果たすことに変わりはない。
音声コマンドを利用して、コンピュータをコントロールするときのエクスペリエンスが、新世代の音声対話システムの登場により、大きく変わってきている。AppleのSiriやGoogle Nowが利用できるようになって数年経ったことで、このテクノロジーは赤ん坊としての時代は終えたといえる。むしろ、今は、幼児期といっていいだろう。つまり、歩いたり、話したりしはじめたところだが、まだ何度も転ぶし、まったく意味のわからないことをしゃべっていることも多い、といった感じである。
Echo: レス・イズ・モア?
SiriやGoogle Nowはスマートフォンに内蔵されている。しかし、Amazonの最新の音声対話システムであるEchoのアプローチはそれらとは異なっていて、モバイルのオペレーティングシステムの一部ではなく、据え置き型デバイスによって、音声対話を提供するものである。

紙の上では、SiriとGoogle Now、Alexa(Echoに話しかけるときに使う名前)はほとんど同じようにみえる。どれも「起動用のフレーズ(activation phrase)」をずっと待っていて、音楽の再生、情報の検索、タイマーの設定といったタスクについてのユーザーの指示を実行する。
おもしろいのは、Echoの発売がSiriやGoogle Nowの数年後であるのに、そうしたシステムに比べて、Alexaがたいして賢くないということだ。以下で、その3つのシステムすべてに同じ質問をした際の結果を見てみよう:
鶏肉は何度で調理すべき?
Google Now: 「華氏165度(訳注:摂氏約75度)。Kitchen Fact(訳注:アメリカの料理サイト)によると、鶏肉中心部の安全な調理温度は華氏165度です」
Siri: 「それについて確認します…はい、鶏肉は何度で調理すべきかについての情報をWebで見つけました…ご覧ください:」
Alexa: 「すみません。お聞きした質問の意味が理解できませんでした」
Alexaがちょっと間抜けであるのは明らかだ。また、SiriとGoogle Nowが提供している決定的なあるものが彼女にはない。それは、視覚的なアウトプットを示すための画面である。Echoにはスマートフォン用のコンパニオンアプリもあるにはあるが、それは設定の調節などの補助的な機能に重点を置いたものである。したがって、主要なインタラクションはデバイス自体を使っておこなわれるわけだが、Echoは基本的にはコンピュータなので、壁のコンセントに常につながっていなければならないし、付いているのはスピーカーとマイクだけだ。つまり、Echoには画面がないので、検索結果のリストといった情報量の多いアウトプットを表示することは不可能なのである。
一見したところ、Echoは大きく後退しているかのように思える。テクノロジー愛好家のほとんどは新製品のアーリーアダプターであることが多く、SiriやGoogle Nowが搭載されたスマートフォンをすでに所有しているだろうと思うとなおさらそう感じられる。
では、なぜユーザーはすでに所有しているものよりも機能が少ないデバイスにお金を払おうと思うのだろうか。
エラーの防止
伝統的なユーザビリティヒューリスティックのひとつにエラーの防止がある。この概念は、単にユーザーをエラーから復帰しやすくするというよりも、システム自体がエラーの発生を防ぐべきであるというものだ。近年、音声認識が向上するにつれて、自然言語理解に関するエラーは激減している。この傾向は音声対話システム全体に対しても続いてほしいものだが。
しかし、スマートフォンベースの音声対話において起こりやすいエラーが明らかにある。それは起動用のフレーズをまったく検出できないというものだ。この問題はその環境で複数の音が流れている場合、たとえば、以下の動画にあるように、デバイスが音楽を再生中に、その音楽を止めるというコマンドを与えるといったような場合には、特によく起こる:
上の動画の内容にあるように、たとえば音楽のような邪魔になるノイズがあると、Siriは音声コマンドを検出できないことが多い。また、デバイスが比較的遠くにある場合、あるいはポケットやバッグにデバイスが入っている場合にも、Siriは音声コマンドを無視することがある。タイマーをセット済みで、あとどのくらい時間が残っているかを知りたいと思って、Siriを使うと、その典型的なエクスペリエンスは以下のようになるかもしれない:
(携帯電話をポケットに入れた状態で)
Hey Siri、あとどれくらい時間は残っている?(how much time is left?)Siri:
(携帯電話をポケットから取り出して)
Hey Siri、あとどれくらい時間は残っている?(how much time is left?)Siri: Timesについての記事を見つけました。読んで聞かせましょうか?
そうじゃなくて、タイマーの時間はあとどれくらい残っている?(how much time is left on the timer?)
Siri: これがタイマーです。8分8秒経過したところです。
一方、Echoでは音声対話が何にもまして優先されている。内蔵マイクが7個もあり、音声コマンドをバックグラウンドノイズと区別することが最も重視されているのである(それとは対照的に、iPhone 6sは小型モバイルデバイスに画面をつけたものであり、組み込みマイクは2個しかない)。この結果は劇的なものだ。つまり、ポケットから取り出すかどうかを気にする必要はまったくないし、Alexaは部屋の反対側からであっても確実な答えを返してくれるのである:
Alexa、あとどれくらい時間は残っている?
Alexa: およそ6分10秒です。
音声認識の優秀さ以外にも、上の2つの例では意味処理の仕方にも違いがある。Alexaは「time」をタイマーという機器を指すものとして解釈しているが、SiriはそれをWebの一般的な検索キーワードと仮定し、「timer」という特定のキーワードが追加されるまで、その言葉を機器としてのタイマーに関連付けることができなかった。音声入力によって、キーワードを効率よくWeb検索できるというSiriの能力に価値があるのは間違いない。しかし、ユーザーの質問をWeb検索として解釈してしまうというバイアスは、Web検索以外のタスクをおこなうときにはエラー率を実際に上げてしまう可能性がある。機能をより重視したEchoの利点は、タイマーが複数必要な場合(これは料理中にはそう珍しいことではない)、さらにはっきりする。新たなタイマーをセットするように頼むと、Alexaはすぐにこのように答えてくれる。「2個目のタイマーを40分でセットしました。では開始します」。一方、タイマーがひとつしかないSiriは次のように難色を示す。「あなたのセットしたタイマーはすでに9分42秒経過したところです。それを変更しますか」。
しかし、Siriの音声検出が性能的に劣るからといって、常にうまくいかないというわけでもない。そうなるかどうかはタスクによる。たとえば、情報を検索している場合には、普通は検索結果の詳細を確認するために、どのみち、画面の近くにいる必要があるので、携帯電話をポケットから出すことによって、タスクにかかる時間が音声制御なしでおこなう場合より増えるというわけでもない。また、いずれにしろ、コマンドは口でいうほうが入力するよりも速いだろう。
しかし、すぐに終わるタスクの場合には、最初にコマンドを聞き取れないと、すぐに形勢は逆転してしまう。そうなると、音声システムのほうが、デジタルタイマーをチラッと見るとか、部屋を横切って照明のスイッチをオンにするといった既存の物理的な代替手段よりも、面倒で時間がかかるということにもなりかねない。新しいテクノロジーはタスクをより速く、容易に実行できるものでないと、既存のツールに対する有望な代用品にはなれない。すぐに終わるタスクの場合には、音声検出がエラーになると、こうしたことは不可能になってしまうのである。
柔軟性と効率
離れたところから、バックグラウンドノイズがあるにもかかわらず、音声コマンドを検出できるAlexaの優れた精度は、ほかの主要なユーザビリティ原則にも影響を及ぼすものである。すなわち、システムはどの程度の柔軟性と効率を提供すべきなのだろうか。
スマートフォンの音声対話システムはどこにでも持っていくことが可能だ。一方、Echoはサイズが大きく、常に電源が必要なため、家庭環境内でしか機能できないという制約がある。しかし、逆説的ではあるが、家庭環境においては、この多少、不格好なデバイスはユーザーに対して非常に柔軟である。つまり、ユーザーはこれを常に持ち歩かなくても、このデバイスの機能にすぐにアクセスが可能だ。その結果、このデバイスはさまざまなやり方やタイミングで使える。たとえば、料理のような別のタスクを実行している途中でAlexaに話しかけることもできるし、身体に障害があって動作に制約がある場合、あるいは単に起き上がる気になれないときにベッドやソファから話しかけることも可能だ。
この種の純粋な音声制御は必然的に起動用のフレーズをずっと待ち続けることになる。自分のいうすべての言葉がデバイスによってモニターされているというのは気味が悪いように思えるが、この音声認識デバイスが実際、それほど出しゃばりでないことはすぐにわかる。というのも、持ち運ぶことを忘れないようにする必要もないし、忘れずに持ち出して、同伴者の顔ではなく、これをじっと見なければならないということもないからだ。
その一方、Echoの最大の欠点のひとつはある種のタスクがあまりにも非効率なままであることだ。買い物リストにアイテムをひとつ追加することは容易にすぐできるのだが、複数のアイテムを追加しようと思うと、それはすぐ、時間のかかる繰り返しの行為となる。ひとつひとつのアイテムに対して、起動用の言葉をいってから、コマンドを伝え、そのあと、言葉による確認を待ってから、次のアイテムでも同じプロセスを繰り返さなければならないからである。その結果、対話は以下のようになる:
ユーザー: Alexa、買い物リストに牛乳を追加して。
Alexa: 買い物リストに牛乳を追加しました。
ユーザー: Alexa、食料品のリストに卵を追加して。
Alexa: 買い物リストに卵を追加しました。
ユーザー: Alexa、買い物リストにバターを入れて。
Alexa: 買い物リストにバターを追加しました。
ユーザー: Alexa、買い物リストにシリアルを追加して。
Alexa: 買い物リストにシリアルを追加しました。
ユーザー: Alexa、買い物リストにチェダーチーズを入れて。
Alexa: 買い物リストにチェダーチーズを追加しました。
ユーザー: Alexa、買い物リストに砂糖と小麦粉、塩を入れて。
Alexa: 買い物リストに砂糖小麦粉塩を追加しました。
3番目のアイテムをいったあとくらいから、これをもっと速くやる方法があるに違いないと普通は考え始めるだろう。いくつかのアイテムをまとめていえば、このプロセスはショートカットが可能ではある。しかし、以下にあるように、できあがったリストではそのテキストの文字列全体がひとつのアイテムとしてリストアップされることになる。
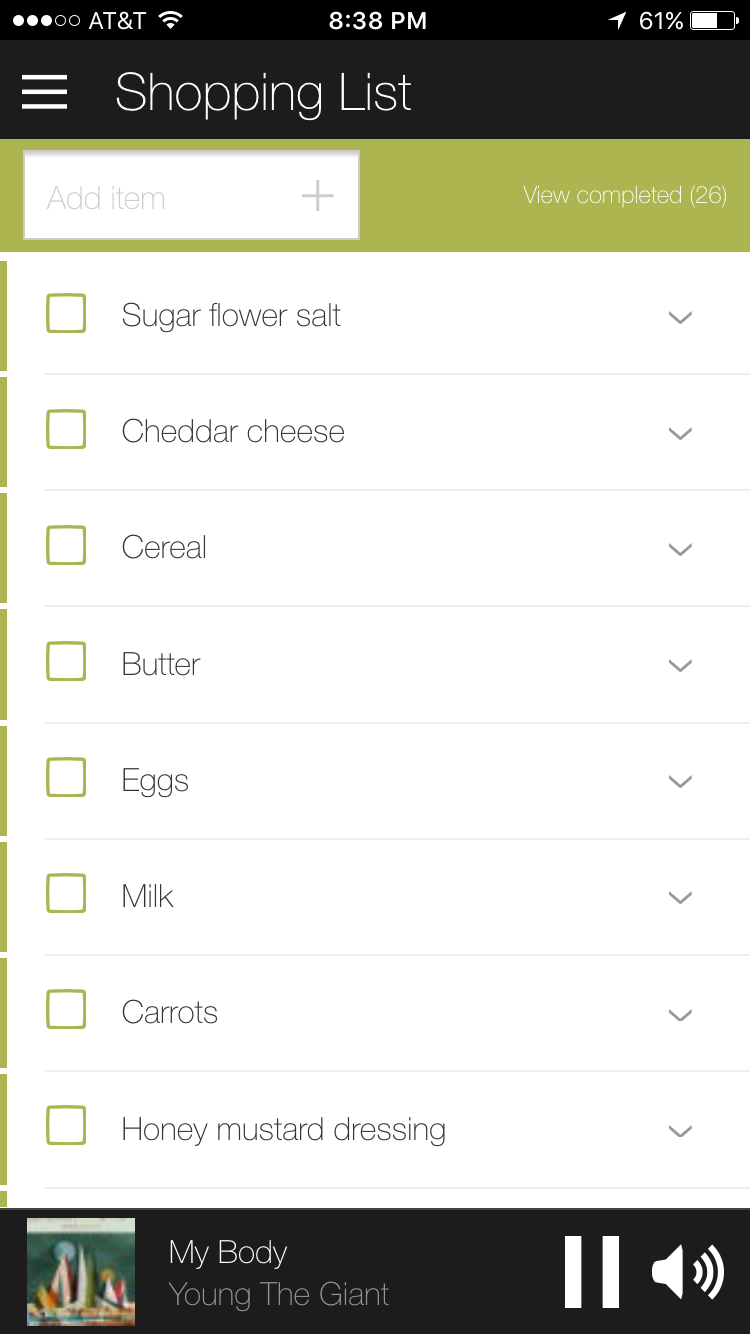
結論
ユーザビリティヒューリスティックの遵守という点では、AlexaにはほかにもSiriやGoogle Nowに劣るところがある。それは主に画面がないことに起因している:
- 見た目でシステムの状況を示すものは、生き生きと光るリングしかない。これはうまく考えられたやり方ではあるけれども、画面による情報量の多いテキストのフィードバックとは雲泥の差がある。
- 音声だけのインタフェースは、再生よりも再認のサポートにもかなり制約となる。というのも、ユーザーはオプションのリストを挙げていく際にも、オプションの選択をしながら、それをワーキングメモリー内に記憶しておく必要があるからである。
新しいテクノロジーが現れると、その新しいテクノロジーにふさわしい手法や原則をゼロから作り直す必要がある、とテクノロジー愛好家は早々に言い放つことが多い。確かに、視覚ディスプレイをなくすことで、インタラクションに関するエクスペリエンスは大きく変わるだろう。しかし、アウトプットが視覚的なものから聴覚的なものに変わったからといって、すべてのルールが変わってしまうのだろうか。
そのテクノロジーがどんなに他と違うものであれ、それを利用する人間まで変わってしまったわけではない。また、ユーザビリティ原則のほとんどはテクノロジーよりも人間の能力や欠点に関係がある。(この記事で論じられているそうした不変のデザイン原則には、エラーの防止、柔軟性、効率、システム状況の可視性、再認vs再生、がある)。Echoは独自の価値を提供する。それは悪くない音声対話システムをすでに所有しているユーザーに対しても、だ。音声という手段はほかの手段とは大きく異なるものではある。しかし、Echoを利用中のイライラするエラーと、魔法のようにうまくいく瞬間というエクスペリエンスの両方が、実証済みのユーザビリティヒューリスティックに端を発しているのは明らかなのである。
変更履歴:原文のページにあった動画をこちらにも掲載しました。また、“voice interaction”の訳語を、「音声インタラクション」から「音声対話」に変更しました。(2018年1月26日)
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。