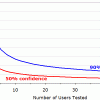
被験者間と被験者内の実験計画
ユーザーに参加してもらう調査において、グループ間計画は学習効果を軽減する。一方、反復測定計画を用いれば、必要な参加者を少なくして、ランダムノイズを最小限に抑えられる。
1回の調査で複数のユーザーインタフェースを比較したい場合、こうした複数の条件をテスト参加者に割り当てる方法には以下の2つがある:
- 被験者間(グループ間)実験計画:異なるユーザーがそれぞれの条件をテストする。つまり、各ユーザーが目にするユーザーインタフェースは1つのみである。
- 被験者内(反復測定)実験計画:同じユーザーがすべての条件(すなわち、すべてのユーザーインタフェース)をテストする。
(なお、ここで使われている「計画」(design)という言葉は「実験の計画」のことを指しているのであって、Webサイトの計画のことを言っているのではない)
たとえば、AとBという2つのレンタカーサイトを比較したいので、各サイトで参加者がどのようにレンタカーを予約するかを調べる場合、この調査は以下の2つの方法でデザイン可能だが、そのどちらのやり方も完全に理にかなったものである:
- 被験者間:各参加者はレンタカーサイトを1つだけテストし、そのサイトでのみ、レンタカーを予約することになる。
- 被験者内:各参加者は両方のレンタカーサイトをテストし、それぞれのサイトでレンタカーを予約することになる。
テスト条件が複数あるユーザー調査ならどんな種類のものでも、被験者間計画にするのか、被験者内計画にするのかを決定する必要がある。とはいえ、この判断は定量調査には特に重要である。
定量調査の実験計画
定性調査と違って、定量的なユーザビリティ調査の目的は、統計的にユーザー全体に一般化できそうな調査結果を得ることにある。こうした調査からのデータをどのように分析するのかは、その調査がどのように計画されているか(すなわち、その調査の実験計画)による。
定量的ユーザビリティ調査の主な目的は、たとえば、あるサイトと競合他社のサイトの、または、デザインの2回の反復結果同士の、または、(エキスパートユーザーと初心者のような)2つのユーザーグループ同士の、といった比較であることが多い。因果関係を発見したい科学実験と同じく、定量調査には以下の2種類の変数が必要である:
- リサーチャーが直接操作する独立変数
- 測定対象である(そして、独立変数を操作することによって変化することが予想される)従属変数
(その調査からもたらされた結果が統計的に有意な場合、独立変数の変化が従属変数の変化の「原因である」と言うことができる)。
では、最初のレンタカーの例に戻ろう。レンタカー予約というタスクで、AとBの2つのサイトのどちらが優れているのかを測定したいのなら、(AとBという2つの取りうる値(「水準」)をもつ)「サイト」を独立変数として選択し、タスク時間とレンタカーの予約の正確さを従属変数にすればよい。この調査の目的は、サイトを変化させたときに従属変数(時間と正確さ)が変化するか、あるいは、変わらないままなのかを確認することである。(もし従属変数が変わらないままなら、それはどちらかのサイトのほうが優れているというわけではないということだ)。
調査を計画するために答えを出さなければならない次の質問は、実験計画を被験者間にすべきか、それとも被験者内にすべきか、すなわち、調査の参加者は調査にある独立変数のすべての条件を経験すべきなのか(被験者内)、それとも1つの条件だけを経験すべきなのか(被験者間)、ということだ。そして、実験計画の選択は、そのデータに使用する統計分析の種類に影響を及ぼすことになる。
被験者内と被験者間の両方の実験計画が用いられることもある。たとえば、レンタカー調査の事例で、30歳未満の参加者のパフォーマンスが、それより上の年齢の参加者と比べてどうなのか、ということにも興味があるとしよう。この場合の独立変数は以下の2つである:
- 30歳未満と30代以上という2つの水準を持つ、「年齢」。
- AとBという2つの水準を持つ、「サイト」。
この調査では、各年齢層で同数の参加者をリクルートすることになる。そして、(30歳未満であろうと30歳以上であろうと)各参加者にはサイトAとサイトBの両方でレンタカーの予約をしてもらうことにしたとしよう。この場合、調査は、「サイト」という独立変数に関しては、被験者内である(各参加者が、この変数のサイトAとサイトBという両方の水準を目にするから)。しかしながら、「年齢」に関しては、この調査は被験者間である。というのも、参加者はそれぞれ1つの年齢グループにしか該当しないからだ(30歳未満か、30歳以上のどちらかであって、両方ということはない)。(まぁ、厳密に言えば、30歳未満のグループを1つ選んで、彼らが30歳になるまで待って、もう1回、そのサイトをテストしてもらうことは可能ではある。しかし、実際にはほとんどの場合、この設定を実現するのは非常に難しいだろう)。
独立変数の中には、特定の実験計画を選ばざるをえないものもある。先ほど見たように、「年齢」はその1つだ。(エキスパートユーザーと初心者を比較したい場合の)「専門知識」、(出張旅行者と観光旅行者といった、異なるユーザーグループやペルソナを比較したい場合の)「ユーザータイプ」、(1人の人が同時に複数の性別にはなれないことを前提にした)「性別」などもそうだろう。ユーザビリティ以外で被験者間計画がよく使われる事例には、臨床試験がある。参加者に治療として与えられるのは、テスト対象の薬か偽薬のどちらか1つのみで、両方与えられることはないからだ。また、操作自体によって、参加者の状態が変化してしまう場合もある。たとえば、読解を教えるには2つのカリキュラムのどちらがより有効かを確認したいのなら、同じ生徒に2つのカリキュラムを受けさせることはできない。いったん読み方を学んでしまえば、そのやり方を忘れ去るのは不可能だからだ。
被験者間と被験者内のどちらがいいのか
残念ながら、この質問に答えるのは容易ではない。上記のように、独立変数によって実験計画が決まってしまうこともある。しかし、多くの場合、どちらの実験計画でも利用することは可能である。
- 被験者間は、条件間の学習と転移を最小限に抑える。片方のレンタカーサイトで一連のタスクを達成してしまうと、そのユーザーは以前よりもその領域についての知識を持つ。たとえば、レンタカーのサイトでは21歳未満のドライバーには割増料金が請求されることや、自車両損害補償制度が何であるかをこのユーザーはもう知っている可能性がある。たとえ、2番目のレンタカーサイトが最初に見たものとはかなり違っていたとしても、そうした知識のおかげで、彼女は2番目のレンタカーサイトではより効率的にタスクを達成できるだろう。
被験者間計画を用いれば、こうした知識の転移という問題は発生しない。参加者が同じ独立変数の水準を複数、目にすることが決してないからである。 - 被験者間調査は、被験者内調査よりもセッションの時間が短い。レンタカーサイトを1つしかテストしない参加者のほうが2つテストする参加者よりもセッションにかかる時間は短くてすむからだ。セッションは短いほうがユーザーが疲れにくい(飽きにくい)。また、(とりわけ、UserZoomのようなツールでは、セッションの時間をかなり短くしなければならないことが多いので)モデレーターのいないリモートユーザビリティテストにも、被験者間のほうが適切だろう。
- 特に独立変数が複数あるときは、被験者間実験のほうが設定が容易である。調査を被験者内でおこなうときは、刺激をランダムに提示して、順序効果が出ないようにする必要があるからだ。たとえば、例のレンタカー調査では、参加者が常に、まずサイトAをテストしてから、その後、サイトBに移る、ということにならないように注意しなければならない。サイトをテストする順番は参加者ごとにランダムになっている必要がある。サイトが2つだけなら、ランダム化は容易である。ユーザーを50%ずつ、それぞれのサイトから始めるようにランダムに割り当てればよい。しかし、独立変数の数や独立変数の水準が増えるにつれて、定量的ユーザビリティ調査のいくつかある既存のプラットフォーム内でランダム化をおこなうのは難しくなる。
- 被験者内計画は、必要とする参加者が少ないので、実施費用が安価である。2条件間の統計的な有意差を検出するには、条件ごとにかなりの数の(たいていは30人以上)データポイントを必要とすることが多い。被験者内計画を用いれば、各参加者から独立変数の水準ごとのデータポイントを入手できる。レンタカー調査でいうと、参加者が30人いれば両方のサイトのデータポイントを入手することができる。しかし、調査が被験者間の場合は、同じ数のデータポイントを集めるのにその2倍の数の参加者が必要だ。つまり、コストも2倍になってしまう。
- 被験者内計画は、ランダムノイズを最小限に抑える。おそらく、被験者内計画の最も重要なメリットは、条件間に存在している真の差が検出されないままになったり、ランダムノイズによって隠れてしまうことを防いでくれるということだろう。
参加者はそれぞれ、自分自身の過去や予備知識、コンテキストをテストに持ち込む。夜遅くまでのパーティの後で疲れている人もいれば、退屈している人もいるだろうし、調査の直前に素晴らしい知らせがあり、幸せを感じている人もいるかもしれない。同じ参加者が変数のすべての水準とインタラクトすると、すべての水準にその人の影響が同じように及ぶことになる。幸せな人は両方のサイトで幸せだろうし、疲れている人は両方で疲れているはずだからだ。しかし、もし調査が被験者間の場合、幸せな参加者は1つのサイトとしかインタラクトしないので、その人の影響が及ぶのは片方のサイトの最終結果のみとなる。もう片方のグループにも同じくらい幸せな参加者を確実に見つけてこないと、この参加者の影響を打ち消すことはできないだろう。
現実問題として、参加者間のこうした違いをリサーチャーが見極めることは不可能だ。性別やテクノロジーに対する経験、年齢層を一致させたとしても、それ以外の各参加者固有の要素を予測したり、見抜いたりすることは難しいだろう。
ランダム化:どちらの実験計画にも不可欠
実験計画が被験者内であれ被験者間であれ、ランダム化には関心をもつ必要がある。とはいえ、気にしなければならないことはそれぞれで少し異なっている。
先ほど、被験者内計画では、なぜランダム化が重要であるのか、ということを論じた。ランダム化によって、起こりうる順序効果を防ぎ、条件間の転移と学習を最小限に抑えることができる、というのがその理由だった。
一方、被験者間計画では、条件をランダムに参加者に割り当てる必要がある。参加者への割り当て方によって、調査結果に影響が出ることが絶対にないようにするべきだからだ。つまり、もしリサーチャーが自分の気に入った参加者全員にサイトAとインタラクトしてもらうということにした結果、サイトAのほうがサイトBよりもパフォーマンスが良かったとしたら、リサーチャーがサイト間の真の差を発見できたのか、それとも、彼がおこなった割り当ての結果が単に反映されただけなのかは判断できないということだ。(たとえば、自分が好かれていることに気づくと、人はその好意に報いようとするものなので、テスト中、我慢強くなったり、前向きに考えたりする可能性があるからだ)。
個人的な好みのような露骨なバイアスがなくても、ランダム化というのは間違えやすいものだ。仮に、土曜から火曜の4日間にわたって、調査を実施するとしよう。そこで、前半のユーザーはサイトAから始めてもらうことにして、後半のユーザーはサイトBから始めてもらうことにするということもあるかもしれない。しかしながら、これは真のランダム化ではない。週末の調査に応じがちがちなユーザータイプと、平日のテスト枠に参加しようとする傾向のユーザータイプがいるという可能性が非常に高いからだ。
結論
ユーザー調査が被験者間なのか、被験者内なのかは(または、その両方なのかは)、各参加者に1つの条件だけを経験してもらうのか、あるいは調査内のさまざまな条件を全部経験してもらうのかによって決まる。こうした実験計画にはそれぞれメリットとデメリットがある。被験者内計画は必要とする参加者の数が少なく、条件間の真の差が発見しやすい。一方、被験者間計画は条件間の学習効果を最小限に抑え、セッションを短時間にし、設定や分析が容易である。
(U-Site編集部注:人の心の仕組みを解明しようとする心理学実験とは異なり、ユーザビリティテストの場合、実験の対象はあくまでUIであって人ではないため、テストユーザーのことは「被験者」(subject)というより「参加者」(participant)と呼ぶほうが適切と思われますが、ここでは、原文のとおり、実験計画の用語として「被験者」という言葉を用いています)
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。