定量的ユーザビリティ調査の参加者数:
サンプルサイズの推奨値に関するまとめ
ほとんどの定量的調査の適切な参加者数は40人だが、リクルートするユーザーをさらに減らしてもよい場合もある。
定量的なユーザビリティテストに必要とされる正確な参加者数にはいろいろなものがある。こうした推奨値(20人から30人、さらに40人以上まで)はお互いに矛盾しているように見えるので、調査担当の新人UXリサーチャーはよく混乱してしまう。(実際に、我々も長年にわたってさまざまな参加者数を推奨してきた)。
こうした推奨値はどこから来ているのか。また、本当に必要な参加者数は何人なのか。これは重要な質問だ。テストの対象者は、少なすぎれば、統計的に信頼できる結果にならない可能性があるし、逆に、多すぎるのは、実質的にはお金を無駄にするということだからだ。結果に自信をもてるだけのデータを集めることと、データを多く集めすぎて貴重な調査資金が無駄にならないこととの、絶妙なバランスを保つ必要があるのである。
ほとんどの場合、我々は、定量調査の参加者は40人を推奨している。この数字の根拠があまり気にならないという人は、ここで読むのをやめてもよい。しかし、この数字の理由や、どういう場合に参加者数を変えてもよいのか、そして、なぜ40人以外の推奨値を目にする機会があるのか、を知りたい人はさらに読み進めてほしい。
これはよくある勘違いなので明確にしておきたいのだが、調査には、定量的なタイプと定性的なタイプの2種類があり、定性調査の目的は知見を得ることで、数値を集めることではないので、統計的有意性は関係ない。これに対して、定量調査の趣旨はUX指標を収集することなので、集めた数値が正しいものかどうかを確認する必要がある。また、この記事は定量調査について書かれたもので、定性調査についてのものではないということも言っておきたい。(定性調査は少数のユーザーしか必要としないが、この記事で論じるのはそういうことではないということだ)。
参加者40人というガイドラインに込められたもの:40人の参加者が必要な理由
定量的なユーザビリティ調査を実施する際、我々はユーザーエクスペリエンスのいろいろな側面を表す数値である、UX指標を収集する。
たとえば、旅行予約サイトのExpediaで、ユーザーの何パーセントがホテルの部屋を予約できるかを知りたいとしよう。Expediaのユーザー全員にホテルの部屋を予約してもらうように依頼することは不可能だ。その代わりに、ターゲット母集団であるExpediaユーザーのうちの一部のユーザーにホテルの予約をしてもらう調査を実施する。
それから、その調査の参加者のうちの何人がこのタスクを完了することができたかを数えて、その割合を使って母集団での割合を推定する。もちろん、この調査から得られた結果が母集団の成功率とまったく同じになるわけではない(多少の測定誤差は常にある)。しかし、その値にほぼ近い値が出ることを期待しているのである。
調査に参加するユーザーの数が少ないと、調査で得られた割合から母集団の成功率を予測できないおそれがある。ユーザー数が少ないとノイズが多くなりすぎるからだ。
別の例として、ドイツ・ベルリンの夏の1日の平均気温を算出したいとしよう。そこで、この平均を出すのに、1日の気温を3日分のみ無作為に調べて、その平均を出すことにした。だが、その3日間だけでは、おそらくあまり正確な数値は得られないのではないだろうか。これは定量調査でサンプルサイズが小さいことによる問題である。
定量的なユーザビリティ調査で、母集団全体の行動をある程度信頼できる形で予測するには、約40個のデータポイントが必要である。しかし、どの程度、リスクを取るつもりがあるのか、そして、何を具体的に測定しようとしているのかによって、この数字は微妙に変わってくる。
40人という参加者の推奨値はある計算によるものである。この計算は、ある調査に基づいて、ユーザー母集団の行動を合理的に予測するために必要なユーザーの最少人数を推定したものだ。特定の前提条件はあるが、この人数は多くの定量的ユーザビリティ調査に有効だろう。
統計学に興味がない場合は、この時点で読むのをやめてもよい(あるいは、結論に直接、飛んでもよい)。しかし、この推奨値に隠れている微妙な部分が気になるそれ以外の人は、このまま読みつづけてほしい。
参加者40人というガイドラインの前提条件
統計学的には、この40人という参加者のガイドラインは、非常に具体的な状況を条件として想定している。そのため、あなた方のシナリオに当てはまることもあれば、当てはまらないこともあるだろう。このガイドラインは、ユーザーの母集団が大きいことと(500人以上)、以下の条件が当てはまることが前提になっている:
- 成功率やコンバージョン率などの二項対立的な指標を、ユーザーの母集団のサンプルを使用した調査に基づいて推定したい。
- 許容誤差15%を目標にしている。つまり、真の値(たとえば、母集団全体の成功率やコンバージョン率)が、測定値(調査から得られた割合)の15%以内の範囲に収まるようにしたい。
- この予測が外れるリスクがほとんどないようにしたい(つまり、許容誤差の計算には95%の信頼度を用いる)。
上記のすべてが当てはまる場合、調査に必要な参加者数を計算すると、それが39人であることがわかる。そこで、我々は端数を切り上げて40人とした。これが上記の推奨値の由来だ。(こうした推定値は、端数を数人分切り上げることが多い。第一に、端数を切り上げたほうが覚えやすい数字になること、二番目には、少し多めに参加者をリクルートしておいたほうが、1人か2人の参加者に何か問題が発生し、そのデータを削除しなければならない場合に役立つからだ。たとえば、調査中に、ユーザーを代表していない人や不正行為者を誤ってリクルートしてしまったとわかることもあるだろう)。
参加者が少なくてもうまくいく場合
上記の前提条件の後ろの2つに当てはまらない場合は、参加者を減らすことが可能だ。具体的には、以下のような場合がそれに該当する:
- 許容誤差が15%より大きくてもよい。
- より大きなリスクを取ってもよい。
許容誤差が15%より大きくてもよい
許容誤差は、母集団全体の数値が測定値とどの程度異なる可能性があるかを測定値の関数として示したものだ。指標を収集する際には、常に許容誤差(あるいは、信頼区間)を計算する必要がある。つまり、Expediaの調査で、調査参加者の70%が部屋を予約することができて、許容誤差が15%だった場合、母集団全体の完了率(真の値)は70%±15%、すなわち55%から85%の間である可能性があるということになる。
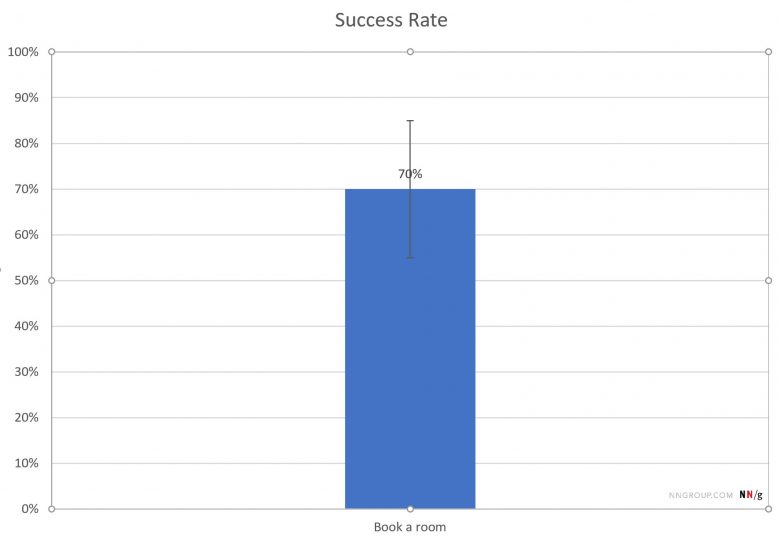
この範囲は30%の幅があり、これは推定値の精度を表している。ただし、状況によっては、もう少し範囲に幅をもたせ、許容誤差が大きくなっても構わないような場合もある(たとえば、UIのある特定の機能をほとんどのユーザーが使うことができる、と言いたい場合など)。とはいえ、許容誤差を20%より大きくすることは推奨しない。真の値の信頼区間が相当広くなってしまい、あまり意味がなくなると考えられるからだ。
より大きなリスクを取ってもよい
95%の信頼度とは、許容誤差の計算が間違う確率が5%のみであるということだ。これは、発表される学術調査の絶対的基準である。しかし、UXリサーチャーのほとんどは、学術調査ではなく応用調査に取り組んでいるので、実際の運用を考えると、もう少しだけリスクを取ってもいいかもしれない。
(結果の信頼性が多少低くなることが壊滅的なリスクでないのなら、リスクを多く取るほうが費用は安くなるので、これは悪いアイデアではない。ただし、UXチームは、定量的なユーザビリティテストを使って、優先順位づけやリソースの配分についての情報を提供することが多いので、信頼性の低いデータはかなり問題になる可能性もあるということは覚えておこう)。
信頼度を90%に下げてもよい場合、許容誤差が15%なら28人、許容誤差が20%ならば15人のユーザーが必要である。繰り返しになるが、こうした場合も、さまざまな正当な理由により(たとえば、データクリーニングをする際に、事前テストの結果の一部を削除しなければならなくなるかもしれない、など)、参加者数の端数の切り上げを検討してもよい。これが、皆さんがどこかで目にしたことのある、30人のユーザー、というガイドラインの根拠である。つまり、30人というこの推奨値を採用する場合は、より多くのリスクを引き受けるということだ。
| 信頼度 | 希望する許容誤差 | 必要な参加者数 | |
|---|---|---|---|
| 低リスク、高精度 | 95% | 15% | 39人 |
| 低リスク、ある程度の精度 | 95% | 20% | 21人 |
| 中リスク、高精度 | 90% | 15% | 28人 |
| 中リスク、ある程度の精度 | 90% | 20% | 15人 |
この表は、二項対立的な指標に対して用いられる信頼度と希望する許容誤差の条件それぞれで、必要となる参加者の数を示したものだ。信頼度が低ければ低いほど、その調査のリスクは高くなる。また、許容誤差が大きければ大きいほど、精度は低くなり、数値の有用性は低下する。
この表は、二項対立的な指標に対して用いられる信頼度と希望する許容誤差の条件それぞれで、必要となる参加者の数を示したものだ。信頼度が低ければ低いほど、その調査のリスクは高くなる。また、許容誤差が大きければ大きいほど、精度は低くなり、数値の有用性は低下する。
連続的な指標の場合はどうなるのか
指標が連続的なもの、あるいは連続的なものとして扱えるもの(たとえば、タスク時間、満足度などの評価、SUSスコアなど)の場合、参加者数の計算式は、ターゲット母集団のばらつきという追加の要因に依存することになる。(また、二項対立的な指標と同様に、希望する許容誤差と使用する信頼度にも依存する)。このばらつきは、パイロット調査を実施することで、そのユーザーグループごとに個別に推定することが可能である。
もちろん、標準偏差を推定するためのパイロット調査は相当に費用がかかるし、この調査自体、かなり多くの参加者を必要とする。一方、ほとんどの定量的ユーザビリティ調査では、いくつかの指標を調査対象にしていて、通常、そのうちの少なくとも1つは二項対立的指標である。したがって、ユーザー数を決める際の制約条件として、そうした二項対立的指標を用いることを推奨したい。言い換えると、成功率、タスク時間、満足度を収集する場合には、単純に、許容誤差15%、90%または95%の信頼度で成功率を調べたい、と言えばよい(そして、30人または40人のユーザーをリクルートすればよい)。そうすることで、調査対象の他の指標の誤差も通常は適切な範囲内に収まるだろう。
ただし、連続的な指標しか収集しないし(これはあまり一般的ではない)、ユーザーグループの標準偏差を推定するための予算もないという場合は、まずは許容誤差をどの程度にしたいのかを決定する必要がある。もちろん、望ましい許容誤差は、測定する対象やタスクの範囲によって異なるが、一般には、平均値の15%または20%を許容誤差とすることを推奨する。つまり、タスク時間が約1分の場合、許容誤差は0.15~0.20分(9~12秒)以下、タスク時間が約10分なら、許容誤差は1.5~2分以下にする必要がある。
そして次に、ヤコブ・ニールセンによる、Webサイトやイントラネット関連の連続的な指標のばらつきの推定を利用すればよい。その推定とは、ばらつきは平均値の52%というものだ。つまり、平均タスク時間が1分の場合、推定標準偏差は0.52×1分=0.52分となる。平均タスク時間が10分であれば、推定標準偏差は0.52×10分=5.2分だ。この推定を追加すると、95%の信頼度で許容誤差が15%の場合は47人、90%の信頼度で許容誤差が15%の場合は33人、95%の信頼度で許容誤差が20%の場合は26人、90%の信頼度で許容誤差が20%の場合は19人のユーザーが必要である。(なお、15%の許容誤差は1分につき0.15分、つまり9秒に相当する)。
| 信頼度 | 希望する許容誤差 (平均値に対する割合として) | 必要な参加者数 | |
|---|---|---|---|
| 低リスク、高精度 | 95% | 15% | 47人 |
| 低リスク、ある程度の精度 | 95% | 20% | 26人 |
| 中リスク、高精度 | 90% | 15% | 33人 |
| 中リスク、ある程度の精度 | 90% | 20% | 19人 |
この表は、タスク時間や満足度などの連続的な指標を対象とする調査に必要な参加者数を示したものだ。信頼度や希望する許容誤差によって参加者の数は異なる。
一般に、ユーザー数は以下の式で求めることができる:
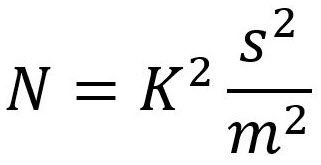
この計算式の変数は以下のとおりである:
- 「K」は定数(95%の信頼度では1.96、90%の信頼度では1.645)。
- 「s」は平均値に対する割合としての標準偏差。
- 「m」は希望する許容誤差で、平均値に対する割合でも表される(0.15は15%に、0.20は20%に相当)。
標準偏差を平均値の52%(または0.52)と見積もる場合の式は以下である:
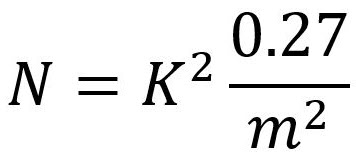
結論
定量的ユーザビリティテストのサンプルサイズの推奨値にはさまざまなものがあるが、それらはお互いに矛盾しているわけではない。単に前提条件が少し異なるだけだ。ユーザーは40人とするガイドラインが最もシンプルで良い結果につながる可能性が高いと我々は考えている。つまり、その人数なら、比較的小さな許容誤差で高い信頼度を確保できる。
ただし、調査結果がユーザーグループの行動を代表していないというリスクを少し余分に取り、その結果、信頼度を90%に下げてもよいというのなら、ユーザー数をさらに少なくする(約30人)ことも可能だ。加えて、さらに大きな誤差も許容できるのであれば、ユーザー数を20人以下に減らすこともできる。しかし、一般的にはその場合のリスクはかなり高いものになるだろう。
(特に、予算が厳しく、タスク時間や満足度などの連続指標を主に調べたい場合は)妥協案として、予算に無理のない範囲でできるだけ多くのユーザー、たとえば、20~25人のユーザーで、まず、調査をするといいだろう。そして、これらのユーザーからデータを収集したら、許容誤差を計算し、それが目的に対して緩すぎるものでないかを判断しよう。誤差が大きすぎる場合は、ユーザーを増やすことを検討しなければならない。ただし、この方法を取るなら、迅速に作業する必要がある。最初の回から時間をおかずに追加の参加者をリクルートできるように、数日のうちに分析をおこなう必要があるからだ。そうしないと、調査の妥当性が損なわれる危険性がある。
データを十分だが多すぎることもないように収集して、定量的な調査を確実に最適化できるように、状況に応じた適切なサンプルサイズを選択してほしい。
定量データを正しく分析して解釈する方法について、さらに詳しくは、我々の1日セミナー「How to Interpret UX Numbers」(UXの数値の解釈のやり方)をチェックしてみてほしい。
参考文献
Jeff Sauro, James Lewis. 2016. Quantifying the User Experience: Practical Statistics for User Research. Elsevier.
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。