UX調査の定性データの分析方法:主題分析
インタビューやフォーカスグループ、日記調査、フィールド調査などのユーザー調査のデータの主要テーマの特定は、しばしば主題分析によっておこなわれる。
定性的なデータのテーマを明らかにするのは骨が折れるし、容易ではない。定量的な調査の場合は比較的わかりやすい。たとえば、競合他社よりも25%良いスコアを獲得した、というように要約できるからだ。だが、定性的な観察結果はどのように要約すればいいだろうか。
プロジェクトの初期段階では、探索的調査がよくおこなわれる。この調査は、多くの場合、以下のような定性データを大量に生み出す:
態度に関する定性的データ:ユーザーインタビューやフォーカスグループ、日記調査から得られるユーザーの思考、信念、自己申告によるニーズなど。
行動に関する定性的データ:コンテキストインタビューなどのエスノグラフィックな方法によって収集されるユーザーの行動に関する観察データなど。
しかし、主題分析をおこなえば(誰にでも実施可能である)、定性データの重要な側面が可視化され、容易にテーマを発見できるようになるだろう。
主題分析とは何か
定義:主題分析(Thematic analysis)とは、個々の観察データや引用を適切なコードでタグづけすることによって、質的調査の豊富なデータを分解して整理し、重要なテーマを発見しやすくする体系的な手法である。
名前が示すように、主題分析では「テーマ」の探索をおこなう。
定義:テーマとは、
- データから発見される信念、習慣、ニーズなどの事象のことを指す。
- 関連のある調査結果が参加者全員またはデータソース全体を通して複数回現れた場合に出現する。
定性データの分析に関する課題
プロジェクトの初期段階におこなわれる探索的調査の定性データに圧倒されてしまうリサーチャーは多い。以下の表で、定性データに関する一般的な課題と、結果として生じる問題を示す。
| 課題 | 結果として生じる問題 |
|---|---|
| 大量のデータ:定性調査によって、読むのに時間がかかる長い発言録と膨大なフィールド調査の記録が生まれる。その結果、パターンを見いだしたり、重要なことを思い出したりするのに苦労する。 | 表面的な分析:単にトピックをすくい上げて、記憶に残るイベントと引用だけを取り上げ、調査記録の大部分が欠落した、非常に表面的な分析になってしまうことが多い。 |
| 豊富なデータ:すべての文や段落に詳細情報が大量に含まれている。しかし、どの詳細情報が有用で、どれが不要であるかを判断するのが難しい。 | 分析が多くの詳細情報の説明になってしまう:分析が、参加者が言ったことやおこなったことの単なる反すうになっており、そうした情報に対する分析的な思考ができていない。 |
| データの矛盾:異なる参加者のデータ間、あるいは同じ参加者のデータ内に、リサーチャーが解明しなければならない矛盾がある場合がある。 | 調査結果が最終的なものになっていない:分析が最終的なものになっていない。参加者のフィードバックに矛盾があったり、さらにひどい場合、リサーチャーの信念に合わない視点が無視されている。 |
| 分析の目標が設定されていない:リサーチャーが詳細情報に夢中になってしまい、最初のデータ収集時の目標を見失っている。 | 無駄な時間と誤った分析:分析が的外れで、調査が間違ったことを伝えている。 |
定性データを分析する際には、何らかの体系的なプロセスがないと、ここで概説したような問題が生じやすい。主題分析をおこなえば、リサーチャーは頭の中が整理されて、作業に集中できるし、定性データを分析するときに従うべき一般的なプロセスを手に入れることもできる。
主題分析を実施するためのツールと方法
主題分析はさまざまなやり方でおこなうことが可能だ。このプロセスに最適なツールや方法は以下の要素に基づいて決定される:
- データ
- データ分析フェーズのコンテキストと制約
- リサーチャー個人の作業スタイル
よくおこなわれる3つの方法は以下である:
- ソフトウェアの利用
- ジャーナリング
- 親和図法の利用
ソフトウェアの利用
定性的なデータを大量に分析するために、定性リサーチャーはしばしばCAQDAS(カクダス。コンピュータ支援質的データ分析ソフトウェア)と呼ばれるソフトウェアを利用する。このソフトウェアプログラムに発言録やフィールド調査の記録をアップロードし、手順に則ったコーディングをすることで、体系的にテキストを分析するのである。このソフトウェアは、ワードツリーやワードクラウドのような、コード化されたデータを多様な方法で操作できるさまざまな視覚化ツールを提供して、テーマの発見を支援してくれる。
利点
- 非常に徹底的な分析ができる。
- (生データと分析を含む)物理的なプロジェクトファイルを他のユーザーと共有可能である。(このやり方が学術機関の学生プロジェクトでは一般的である)。
欠点
- 時間がかかる。結果的に生じる大量のコードを管理可能な小さなリストにまとめる必要があるため。
- 高価である。
- 他のユーザーと一緒に同時に分析するのは難しい。
- ソフトウェアの学習が必要である。
- 制約があるように感じる可能性もある。
ジャーナリング
グラウンデッドセオリー(:質的な社会調査手法の1つ)を実践しているリサーチャーの間では、あるテキストについて頭に浮かんだ思考プロセスやアイデアを文章化することがよくおこなわれる。主題分析としてのジャーナリングは、この方法論を基にしていて、まず自分たちでデータにラベルを付け、その部分を切り出す。そして、その後でこの作業に関するリサーチャーのアイデアと思考プロセスを書き出す。このノートはメモ(memo)と呼ばれる。(従業員にお知らせを伝えるオフィスメモと混同しないようにしよう)。
利点
- 詳細なノートを書くことを通して、じっくり考えることができる。
- テーマに到達した経緯の記録がリサーチャーに残る。
- 柔軟な分析が可能で、費用もかからない。
欠点
- 共同でおこなうのが難しい。
親和図法
データに印をつけて、そこを物理的に、またはデジタル処理で切り取り、物理的またはデジタルのボード上にテーマが現れるまで、意味のあるグループを構成し直す。(親和図法のデモビデオを参照のこと)。
利点
- 共同でおこなうことができる。
- テーマに迅速に到達できる。
- 柔軟な分析が可能で、費用もかからない。
- 見て確認できる。また、反復分析が可能である。
欠点
- 多くの場合、1回しかテキストセグメント(:切り出したテキスト部分)をコード化しないため、他の方法ほどは徹底的な分析にならない。
- データが非常に多様な場合やデータが大量にある場合には実施が難しい。
コードとコーディング
主題分析の方法はどれも、ある程度のコーディング(プログラミング言語でプログラムを書くことではない)を前提としている。
定義:コードとは、テキストセグメントのラベルとして機能する単語または語句のことである。
コードは、該当のテキストの内容の説明で、複雑な情報を簡潔に表現したものだ。(キーワードが記事を説明し、ハッシュタグがツイートを説明するように、コードはデータを説明する)。多くの場合、定性リサーチャーは、各コードに名前を付けるだけでなく、コードの意味とコードに適合するあるいは適合しないテキストの例も提示する。こうした説明や例は、データのコーディングを担当する人が複数いる場合、またはコーディングが長期間にわたっておこなわれる場合に特に役に立つ。
定義:コーディングとは、テキストセグメントに適切なコードのラベルを付けるプロセスのことである。
コードを割り当てると、ほぼ同じような内容のテキストセグメントを容易に識別して比較できる。コードによって情報を楽にソートできるようになり、データを分析して、セグメント間の類似点や相違点、関係を明らかにできるからだ。その結果、我々は本質的なテーマの理解に到達できるようになる。
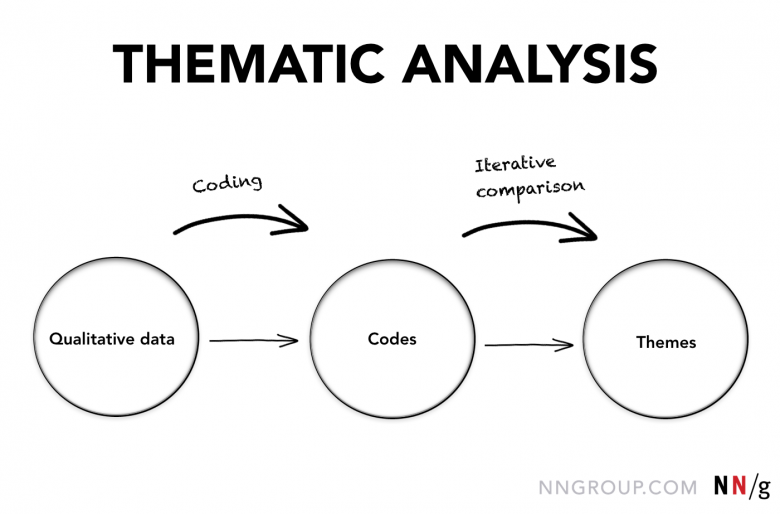
コードの種類:記述的コードと解釈的コード
コードには以下のような種類がある:
- 記述的コード:データの内容を説明する。
- 解釈的コード:データを分析的に解釈し、リサーチャーの解釈という視点をデータに追加する。
記述的コードと解釈的コードの例を見るために、今年初めにUX実践者に対して実施したインタビューからの引用を検討してみよう(このインタビューはUXキャリア調査の一環として実施されたもので、UXキャリアレポート(英語)に掲載されている)。
「私はミーティングの進行をするたびにすごく緊張してしまうので、1日半かかるトレーニングコースに参加するように会社が提案してくれました。そこで、そのコースに行ったのですが、コースのインストラクターのしたことは当時私が一番嫌だと思っていたことでした。でも、今はそれをしてくれたことに本当に感謝しています。我々が最初にしたことは、1枚の紙に自分の名前を記入し、その紙に、調査のモデレーターや進行役をおこなうときの最大の恐怖を書き出すことでした。そして、我々がその紙を提出すると彼は言いました。『はい、では明日はこの紙に書いた状況を皆で演じてもらいます』。(中略)次の日、コースが再開されると、私はその部屋を出ることになり、私が外にいる間、チームの私以外のメンバーは私の最大の恐怖について読み、その状況をどう演じるかを検討しました。その後、私は部屋に戻り、その恐れている状況で、10分間、進行役をしたというわけです。その結果、恐れることは何もなく、実際には恐怖は自分の頭の中に存在していることがほとんどであると受け入れられるようになりました。そして、この体験をすることで自分がこうした状況に対処できることもわかりました」。
上記のテキストに対して考えられる記述的コードと解釈的コードは以下である:
記述的コード:「スキルの取得方法」
コードのラベルの論理的根拠:参加者は、特定のスキルをもつようになった経緯を説明するように依頼された。
解釈的コード:「自己内省」
コードのラベルの論理的根拠:参加者は、この経験がミーティングの進行に関する彼女の信念をどのように変え、自分の恐怖とどのように向き合ったかということを説明している。
主題分析の実施ステップ
利用するツール(ソフトウェア、ジャーナル、親和図法)に関係なく、主題分析の作業は6つのステップで考えることができる。
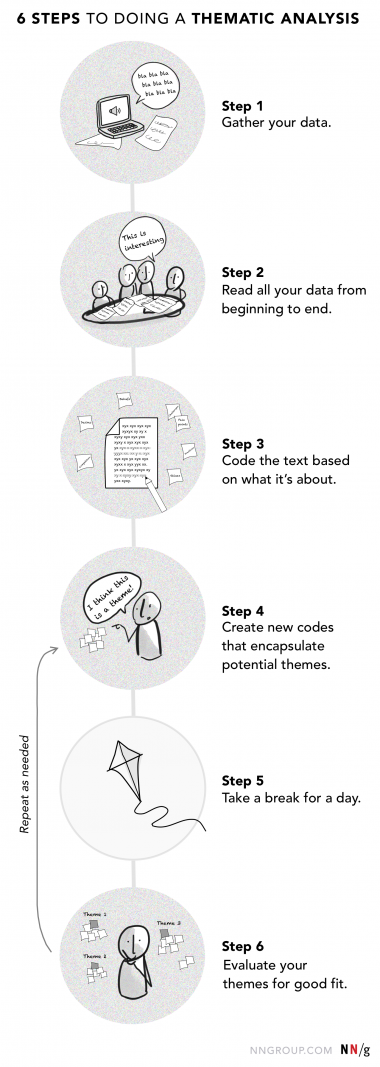
ステップ1:すべてのデータを収集する
インタビューやフォーカスグループの発言録、フィールド調査の記録、日記調査の記入内容などの、生データに取り組むことから始めよう。インタビューの録音を文字に起こして、この発言録を分析に利用し、断片的な記憶に依存しないことを推奨する。
ステップ2:データを最初から最後まですべて読む
たとえ自分がその調査を実施した担当者であったとしても、データを熟知してから分析を開始するようにしよう。分析する前に、発言録やフィールド調査の記録などのデータソースはすべて読もう。チームをこのステップに参加させるとよい。チームに参加してもらうことで、ユーザーについての知識、そして、ユーザーとそのニーズに対する共感がメンバーの中に生まれるのだ。
ワークショップを1回(チームが非常に大規模な場合やデータが多い場合は、数回にわたって)、実施しよう。その際には以下のステップに従うとよい:
- チームメンバーがデータに取り組む前に、ホワイトボードか大きな紙に調査課題を書き、作業中、その調査課題をすぐ参照できるようにしよう。
- 各メンバーに、1人の参加者の発言録またはフィールド調査か日記調査の記録内容を渡し、重要だと思うことにマーカーで印を付けるように指示しよう。
- チームメンバーが内容の読み取りを完了したら、その発言録や記録を他の誰かに渡し、別のチームメンバーから新しい発言録や記録を受け取るようにする。そして、チームメンバー全員がすべてのデータを読むまでこの手順を繰り返す。
- 気づいたことや驚いたことをグループで話し合おう。

チームですべての調査セッションを観察できれば一番いいが、セッションが多かったり、チームの規模が大きいとそれは不可能だろう。個々のチームメンバーが観察したセッションがほんの一部にすぎない場合、そうしたメンバーが調査結果を完全に理解しないまま、チームからいなくなってしまうこともある。しかし、ワークショップをおこなえばこの問題は解決できる。全員がすべてのセッションの発言録を読むことになるからだ。
ステップ3:内容に基づいてテキストをコーディングする
コーディングのステップでは、マーカーの入った部分同士を比較しやすいように、その部分を分類する必要がある。
そして、この時点で、調査の目的を思い出すとよい。調査の課題を印刷し、分析をおこなう部屋の壁やホワイトボードに貼りつけておこう。
十分な時間がある場合は、この最初のコーディングステップにチームを参加させるとよい。時間に制限があり、処理するデータが多い場合は、このステップは自分でおこない、その後、コードを確認して、テーマを具体化する際の手助けをチームに依頼しよう。
コーディング中は、テキストセグメントを1つ1つ確認して、「ここの特徴は何だろう」と自問しよう。そして、その部分の内容を説明する名前を付けよう(記述的コード)。この時点で、テキストに解釈的コードを付けることも可能だ。ただし、通常はもっと後のほうが楽に割り当てることができる。
コードは、データをグループ化する前でも後でも作成可能である。ステップ3の次の2つのセクションでは、コードを追加する方法とタイミングについて説明する。
従来の方法:グループ化の前にコードを作成する
従来のやり方では、文や段落、語句などのデータ区分にマーカーを入れながら、コーディングをしていく。その際、利用するコードをすべて記録し、それぞれがどういうものであるかをまとめておくと役に立つ。そうしておけば、テキストの続き部分をコーディングする際、(特に複数のメンバーでテキストをコーディングしている場合に)このリストを参照できるからだ。また、このやり方を取れば、同じ種類の課題に(後で統合する必要がある)複数のコードを作成することもない。
そして、すべてのテキストをコーディングしたら、同じコードのすべてのデータをグループにする。
このプロセスにCAQDASを利用している場合は、コーディング中に割り当てたコードをソフトウェアが自動的にログに記録してくれるので、そのコードを繰り返し利用することができる。さらに、同じコードでコーディングされたすべてのテキストを見ることもできる。
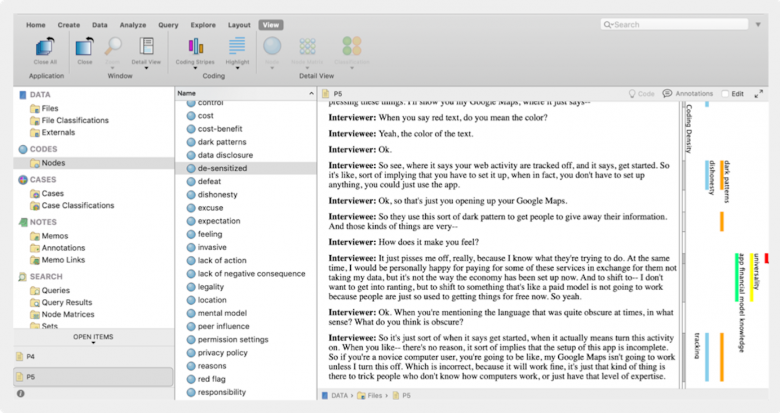
短時間でできる方法:テキストセグメントをグループ化してからコードを割り当てる
この方法では、テキストにマーカーを入れるときにコードを考え出すのではなく、マーカーの入った類似のセグメントをすべて(物理的に、またはデジタル処理で)切り取り、(親和図法で付箋をグループ化するのと同じように)1つのグループにしてから、それにコードを付ける。このグループ化をデジタルでおこなえば、コード化された部分を新しいドキュメントやビジュアルコラボレーションツールに取り込むこともできる。
以下の画像は、グループ化を手動でおこなった場合のものだ。発言録は切り分けられ、付箋に貼られ、同じトピックを示すグループとして違和感がなくなるまで、ボード上であちこち動かされる。そして、それが終わってから、リサーチャーが記述的コードを書いたピンクの付箋をグループに貼りつけている。


このステップでは最後にトピックごとにデータをグループ化し、そこにコードを付ける必要がある。
例をみてみよう。私は家庭での料理について3人にインタビューし、他の料理ではなく、ある特定の料理を作ることにした経緯について、話してもらった。そして、料理中に直面した具体的な課題(たとえば、食事療法の条件、厳しい予算、時間と物理的スペースの不足など)と、これらの課題のいくつかに対する解決策も説明してもらった。
インタビューの発言録にマーカーを入れた切り抜きを、トピックごとにグループ化した後、私は最終的には広範な3つの記述的コードと、それに対応するグループを作成することができた。
- 料理についての経験談:料理に関連する記憶に残る良い経験と嫌な経験
- 問題点:料理をすることを妨げたり、難しくしたりするもの(食事制限とのバランス、予算の制限など)
- 助けになるもの:それぞれの課題や問題点を克服するのに役立つ(または役立つと思われる)もの
ステップ4:テーマ候補になる新しいコードを作成する
すべてのコードを見渡して、因果関係や類似点、相違点、矛盾を調べ、その根底にあるテーマが発見できないかチェックしよう。それをおこないながら、一部のコードを脇に置いて(アーカイブするか削除する)、新しい解釈的コードを作成することになる。ステップ3で説明したような物理的なマッピング方法を取っている場合は、テーマを探索するにつれて、そうした初期のグループは分解されたり、拡張されたりする場合もある。
以下の質問を自問しよう:
- 各グループで何が起こっているのか。
- これらのコード同士はどんな関係か。
- これらのコードは調査の課題とどのように関係しているか。
料理の話に戻ろう。各グループ内のテキストを分析して、データ間の関連性を探っているときに、私は2人の参加者が、調理法がいろいろとあり、さまざまな食材とうまく合う材料が好きだ、と言っていることに気づいた。3人目の参加者は、1回の食事ごとに食材を購入するのではなく、1週間を通していろいろな料理に使える食材のセットが手に入ればいいのに、と述べていた。そこで、食材の柔軟性に関するテーマが新しく浮かび上がってきた。私はこのテーマに対して、「何にでも使える食材」というコードを思いつき、このコードについて詳細な説明を書くことにした。

ステップ5:1日休憩してからデータに戻る
たいていの場合は、休憩を取り、戻ってきてから、新鮮な目でデータを見ることを勧める。そうすることで、データ内の重要なパターンを明確に見いだすことができるし、画期的な知見を導き出しやすい。
ステップ6:テーマの適合性を評価する
このステップでは、周りを巻き込んで、コードや新しく出現したテーマを検討してもらうとよい。それによって、新しい知見が引き出されるだけでなく、新鮮な目と脳による疑問や批評を自分たちの結論に対して得ることができる。こうしたやり方を取ることで、解釈に個人的な偏見が反映される可能性が減る。
テーマを精査する必要がある。以下の質問を自問しよう。
- テーマには、データによる十分な裏づけがあるか。また、そのテーマに反するデータがないか。
- テーマには、事例がたっぷりとあるか。
- 自分1人でデータを分析して見つけ出したテーマに、周りは賛同してくれそうか。
これらの質問に対する答えが「いいえ」の場合は、分析に使ったボードに戻る必要があるだろう。音声データを収集している場合は、ほとんど常にデータから得られるものがさらにあるので、チームでの作業時間を追加して、ステップ4~6を繰り返すとよい。
結論
主題分析は、大量の定性データに効率的に目を通すための有用なガイドとして活用するとよい。主題分析には決まった実施方法はない。収集したデータの種類と量に適した分析方法を選択しよう。可能であれば、分析プロセスに他のメンバーを誘って、分析の精度を上げ、ユーザーの行動や動機、ニーズに関するチームの知識を増やすとよい。分析は時間のかかるプロセスだ。したがって、分析を完了するためのデータ収集にかけるのと同じくらいの時間を分析にも配分しておくことをお勧めする。
さらに詳しく:UX Conferenceにおける1日トレーニングコース「User Interviews, Advanced techniques to uncover values, motivations, and desires」にて。