定量的ユーザビリティでの、正確さ vs. 洞察
ほんのわずかなことを過剰な精度で知ることに予算全部を使うよりは、ユーザビリティ指標の誤差範囲をより広いものとして受け入れるほうが良い。
先週、新しいユーザーエクスペリンス(UX)基礎トレーニングコースのために、調査タイプ別の望ましいテストユーザー数を入れたスライドを作成した。私は基礎的なコースを教えるのが好きである。なぜならば、それはまさにこうした機会、つまり、25年間にわたるユーザビリティプロセス研究の成果を1つの表にまとめ上げる、といった機会を与えてくれるからだ。物事の本質を見るために複雑なテーマを要約すると、パターンというのは形となって現れてくるものなのである。
例えば、なぜ、ユーザビリティ調査よりもカードソーティングのほうがより多くのユーザーをテストしたほうが良いとわざわざ言うのか。それは「テストしているのはシステムであってユーザーではない」といういつものルールがカードソーティングには当てはまらないからである。メンタルモデルを導き出すとき、実際のテスト対象は事前に決まっている人工物ではなく、個々のユーザーであるため、そこではばらつきが大きくなるのである。
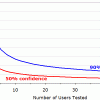
自分の表を見て一番驚いたのは、ほとんどの場合に19%の誤差を含んだサンプルサイズで定量的ユーザーテストをするよう、アドバイスをしていることである。
19%という数字からは不正確な印象を受ける。ではなぜ、ユーザビリティ指標を評価する際にはかなり低いレベルの正確度で十分なのか。
理由は2つある:
- 19%の信頼区間が表しているのは、ほとんど最悪の場合の結果である。通常、エラーというのはもっとずっと少ないからである。
- ウェブサイト間のユーザビリティの違いの平均は64%である。したがって、測定誤差が19%あるという数少ないケースでも、たいていの場合はどのみち正しい勝者を選ぶことになる。
こうした数学的観点によって、予算を節約し、定量調査のサンプル数を中規模に抑えようという考えは十分正しいことがわかる。
しかし、さらに重要性の高い、重要な根拠が2つある。
大きな問題に集中しよう
ユーザビリティでは小さな問題は気にすべきではない。現在のところ、他にもっと大事な問題がまだあるからである。ユーザビリティのためにウェブサイトのデザイン変更をすると、その重要業績評価指標(KPI)の平均改善率は83%にもなる。つまり、ほとんどのウェブサイトは明らかに、依然としてひどいユーザビリティ上の問題を抱えているのである。イントラネットやモバイルのサイトやアプリの状態はさらにひどいことも多い。
したがって、重点的に取り組むべきは、あなた方が提供するユーザーエクスペリンスが顧客のニーズを満たしていないという、デザイン上の本当に重大な問題である。一般に、決定的な影響をもたらす問題は数点しかないものである。1%か2%しか見返りをもたらさない変更点をいじり回すよりも、そうした極めて重要な改善点に対して、重点的に投資するほうが良い。
精度の高すぎる測定結果に予算を浪費することで、重要な問題が簡単に脇に置かれてしまうこともありうる。その結果、そうした取り組みのために残される予算が減ってしまうことは確かだろう。
おそらく20年以内には、ユーザーインタフェースは十分に改善され、我々に残された目標は最後の数パーセントの品質を上げるための微調整になっていくだろう。しかし、今がそうというわけではまったくないのである。
より多くの質問をして、理解を深めよう
たった1つの質問では、得られる答えは1つだけだ。だからこそ、1つの指標のより狭い信頼区間を得るために予算すべてを投じるのではなく、より広範囲のユーザー調査全体にわたって一定の予算を配分するほうが良いのである。
さらに悪いことに、答えが1つしか得られないと何が重要な論点であるかわからない可能性もある。そういう意味では、定量的ユーザビリティ調査はJeopardy(注: アメリカで昔、流行ったクイズ番組。早押しクイズで掛け金を手に入れていく)のゲームに似ている。調査結果から出た答えは42だったかもしれないが、なぜ、そうなのか、次回、スコアを50にするにはデザインをどう変えるべきかはわからない。
そんなわけで、パラレルデザインと反復デザインにお金を使うことを推奨したい。そこではさまざまなユーザーインタフェース上の解決策がユーザーテストという強烈な光にさらされる。もちろん、調査をたくさんすれば、1つ1つの調査の規模は小さくなる。しかし、それで良いのだ。なぜならば、調査全般にわたって、あなた方の洞察は積み重なっていくからだ。より多くの調査=より多くの質問=より多くの答え=デザインが良くなる、というわけである。
とはいうものの、「豪華なユーザビリティ」に対してお金を払う場合もある。しかし、それは主にユーザーエクスペリンスの方法論について、高い成熟度に到達しているごくまれな組織での話である。
小さな調査から樫の大樹は育っていく
1つ1つの調査のサイズを手頃な大きさに保つことに賛成する根拠の最後の1つは、調査を通して洞察を積み重ねていくことに意義があるということである。サイトと顧客の調査を毎年続けるごとに知識は累積していくからである。
例えば、Nielsen Norman Groupはさまざまな研究調査とクライアントからの依頼案件を通して、4,090人のユーザーを対象に1,600個のウェブサイトをテストしてきた。我々は1個1個のサイトを何百人ものユーザーによってテストしてきたわけではないが、キーポイントになるユーザーの行動の多くを何千回と見てきた。したがって、例えば、ユーザーはウェブサイトではコンテンツを流し読みするが、モバイルサイトではさらに読む量が減る傾向がある、と我々が言うときには、その調査結果は、読むのを特に嫌がっている20人の参加者から構成されている調査1件のみを基にしているわけではない。
様々なサイトで様々なプロフィールを持つユーザーが同じ行動をするのを見るとき、それは証拠として積み上げられ、寄与する調査1つ1つに対する信頼区間よりもさらに強固な証拠となっていくのである。
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。