ユーザビリティやUXに関係する4種類の心理学的「事実」(1)
仮説検証型の心理学的「事実」
ユーザビリティ・UXと心理学とを関連づけた書籍が複数出版されている。そこに掲載されている心理学的「事実」とされるものには、幾つかのタイプがある。まず本稿では、そのうちの1つ、仮説検証型について少し詳しく説明してみたい。
ユーザビリティやUXと心理学
ユーザビリティやUXと心理学や行動経済学の話を関連づけた書籍は、僕の手持ちでも数冊ほど出版されている。こうした状況をみると、それなりにHCD関係者の間でも心理学への理解が進んでいるように思われる。
ただし、そうした書籍や心理学のテキストに掲載されている心理学的「事実」とされるものには、実は幾つかのタイプがある。筆者はそれを4つに分類している。仮説検証型、探索型、経験則型、洞察型の4つである。仮説検証型は、仮説をたてて実験や調査でそれを検証して「こうなんだよ!」というタイプ、探索型は、いろいろデータを集めて多変量解析なんかで調べてみたら「こうだったよ」というタイプ、経験則型は、我々が日常的に生活するなかで「こうなんだよね」ということを経験的にすでに知っているので確認できるタイプ、洞察型は、よくわからないことに関して「こうだと思うよ」という仮説的な構造を示したもので実験などによっては検証され得ないようなタイプである。
このシリーズではその4つのタイプについて順に見ていくが、まず本稿では、仮説検証型について少し詳しく説明してみたい。
仮説検証型
まず心理学的な予測を立て、それを実験や調査の結果から経験的に検証し、心理学的事実として提示するアプローチである。心理学やヒューマンインタフェース関連の学会、あるいはHCD-Netなどの大会や研究会、論文誌に発表されている心理学的「事実」の大半はこのタイプである。
その基本的な流れは、まず帰納的に仮説を立て、その仮説から演繹的に幾つかの予測を立て、その予測を実験や調査によって確認することで、遡って仮説の適正さを判定するというものである。これは心理学では一般に仮説演繹法といわれているが、本稿ではわかりやすさを重視して、仮説検証型のアプローチという言い方をする。なお、このアプローチでは仮説が正しいか誤っているかを直接評価しようとするのではなく、仮説から導き出される可能性としての予測(ここに演繹という思考作用が入る)を具体的に列挙し、それらを実験や調査の結果から確認しようとするわけである。実験や調査という検証作業の結果、意味があると考えられれば、前提とした仮説が正しかったとみなすことになる。
最初に立てる仮説の大半は、現実世界の事象や先人の研究結果、自分の調査や観察などから帰納的に設定されるものであるが、時には帰納的に仮説を構築しないもの、つまり、研究者の直感的洞察なり他分野からのアナロジーによって仮説を構築する場合もある。要するに、ポイントとなるのは、その仮説を正しいものと考えたときに、そこから演繹的に導かれる予測を実験なり調査という経験的な手法によって検証することである。
Collins and Quillian (1969)の研究
このやり方を説明するために、一つの事例を取り上げることにしたい。それはCollinsとQuillianが1969年に発表したLTM(長期記憶)における意味記憶の検索について調べたもので、意味記憶の構造に関する古典的な研究として知られている。長期記憶は、エピソード記憶、意味記憶、手続き的記憶などに区別されており、意味記憶は、いろいろな概念がどのように頭の中、つまり長期記憶の中に保存されているかに関わるものである。
彼らは、その意味記憶の構造としてノードとリンクからなる構造をそのベースとして想定した。つまり、概念はノードとして、概念間の関係はノードをつなぐリンクとして表現され、全体として巨大なネットワーク構造になっているという考え方をしている。実際の記憶が生理学的な意味で、脳内におけるそうしたノードとリンクで表されるかはわからないものの、ニューロンという神経細胞の構造とのアナロジーとしては考えやすいものである。また、彼らが所属していたBBN: Bolt Beranek and Newmanという企業は情報処理関連事業を行う会社であり、リンクとノードという考え方は、コンピュータによって脳のシミュレーションを行おうという発想に親和性の高いものだったといえる。
ただし、コンピュータでシミュレーションしようとしても、人間の脳の複雑さを考え出すとキリが無くなる。たとえば「自転車」という概念には、脚の回転運動をタイヤに伝えて前進する車両といった定義、移動とか運搬とか行楽といった概念が関連しており、また自転車の外観や砂利道をゆくときの音などの感覚的イメージもあるし、自宅の電動アシスト自転車はそろそろ充電しておかないといけないといったエピソードも、自転車を動かすときには左右のバランスを取りながらペダルを押し込まなければいけないという手続きの記憶もある。また英語にすればbicycleになるという情報も記憶されている。
しかし、エピソード記憶や意味記憶や手続き記憶が脳内でそれぞれの塊を作っているかどうかはわからないし、一つ一つの概念やイメージや手続きなどが一つのニューロンに対応しているという生理学的な保証もない。要するに、長期記憶の構造については、ほとんどわかっていないというのが現状なのである。その意味で、CollinsとQuillianの研究は大胆な挑戦であったといえる。
さて、ネットワーク構造にはいろいろな切り出し方があるが、彼らは木構造を想定した。木構造というのは生物の系統樹、組織の構造図、家系図など、身の回りの多くの事象の構造を表現するのに使われている。そして、そのように表現でき、表現されたものが理解しやすいということは、人間のLTMにおける意味記憶も類似の構造になっているのではないか、という連想を生んだわけだ。
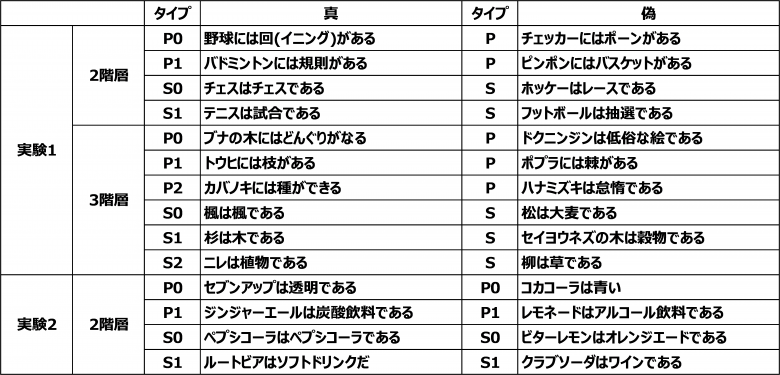
彼らが提示した木構造の例は図1のようなものである。
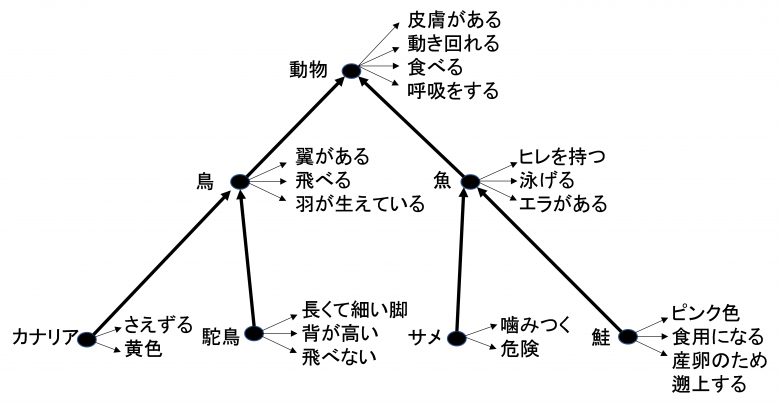
ここで、カナリアや駝鳥などのノードから鳥というノードに、また鳥や魚から動物に向かっている太い矢印は上位集合(S: Superset)を表すもので、英語でいえば「is+名詞」に相当する。また、各ノードに付属している小さな矢印は特性(P: Property)を表すもので、英語では「is+形容詞」、「has+名詞」、「can+動詞」という形になる。この図1が彼らの研究における「仮説」である。
次に「カナリアはカナリアである」という文は同一のものをさしているからレベル0のS、つまりS0であり、「カナリアは鳥である」という文は一つ上の階層を表しているからレベル1のS、つまりS1、そして「カナリアは動物である」という文は2つ上の階層を表しているからレベル2のS、つまりS2である、ということになる。また、特性については、「カナリアは黄色い」であればカナリアの特性であるからPは0でP0、「カナリアは飛べる」という文では、カナリアではなく一つ上位の鳥の特性であるからP1、「カナリアは呼吸をする」であれば、2つ上の動物の特性であるからP2となる。
このようにして、表1のように、それぞれの文のタイプと、それが正しい内容を表しているか、間違っているかを区別して、いくつかの文のサンプルが生成される。英語話者にとっては日常的な単語なのかもしれないが、「A hemlock has buckeyes」のように、翻訳してみると日本人には理解の困難な事例がでてくるのは致し方ないだろう。
そして、彼らは、階層(S)が遠ければ遠いほど、上位集合(S)や特性(P)についての正誤判断には「リンクをたどる分だけ」時間がかかるだろう、と考えた。これがこの実験における「予測」である。
このような文を、2階層については128個の文を、3階層については96の文を用意して、8人の被験者に個別に提示して、文が提示されてから正誤判断が行われるまでの時間を測定した。これが「検証」のための実験である。
実験結果は図2のようになった。
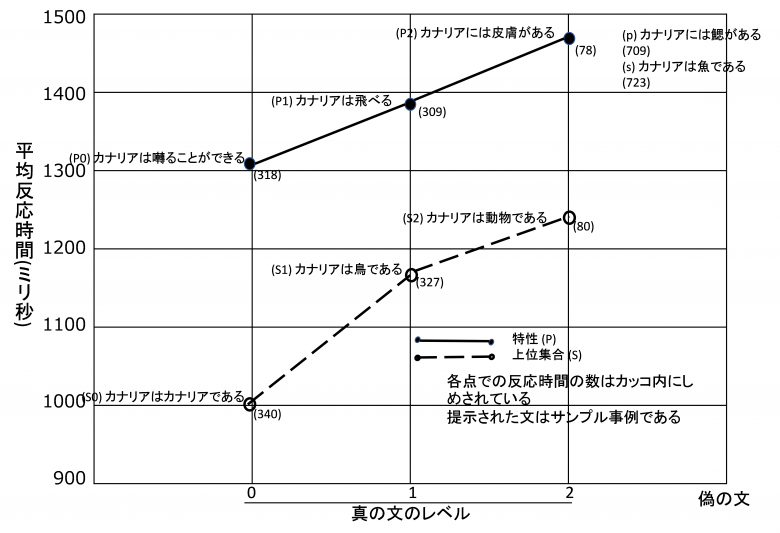
縦軸は反応時間(ミリ秒)であり、横軸は文の内容が真であった場合のレベル(P0, P1, P2, S0, S1, S2)である。グラフを見ると、破線(S)の斜線と実線(P)の斜線は、ほぼ平行に右上がりになっている。つまり、上位集合に検索を進める場合は、集合のノード(S0, S1, S2)についても、特性のノード(P0, P1, P2)についても、上位集合への移動(S0→S1, S1→S2、P0→P1, P1→P2)には一定の時間、およそ75ミリ秒がかかっていることがわかる。また、破線(S)の斜線と直線(P)の斜線の間もほぼ一定で、およそ225ミリ秒がかかっていることがわかる。
彼らは、75ミリ秒という時間には、そのレベルでの特性の検索にかかる時間と上位のレベルに移動する時間が合わさっていると考えた。225ミリ秒が75ミリ秒より長いことから、属性を検索する時間(P)はレベルを移動するよりも長いものであり、さらに属性の検索は並列に行われているのではないか、と考えている。
ともかく、これによって、「仮説」→「予測」→「検証」という流れによって予測の正しさが確認され、さらに仮説の正当性が確認された…という形になる。
Collins and Quillian (1969)の得た結果について
かくして、彼らの1969年、今から53年前になる時期の実験結果は、仮説検証型の典型的な成果として、現在でも心理学や情報科学のテキストに引用されているほどになった。
しかし、こうした仮説検証型の研究については、結果を受け止めるときに注意しなければならないことが多い。たとえば、日経新聞(2019.12.15)には、
米科学誌「サイエンス」は15年、心理学研究への信頼が揺らいでいる事態を重く見て、主要な学術誌に掲載された心理学と社会科学の100本の論文が再現できるかどうかを検証した。結果は衝撃的で、同じ結果が得られたのはわずか4割弱にとどまった。日本の代表的な心理学会誌「心理学評論」も16年、再現できない実験に関する問題を特集号として取り上げた。
日経新聞(2019.12.15)
という記事が紹介されている。仮説検証型の研究については、こうした危険性もあることを知っておく必要があるだろう。また、統計的な手法を利用して、実験仮説が検証されたかどうかを確認するという点についても、サンプルサイズの拡大、つまり実験の試行回数を多くすれば多くするほど統計的に有意とされる可能性が高くなってしまう、というバイアスの存在することも知られている。
さらに、論文として書かれている内容について、そのロジックをきちんと分析することも必要である。たとえば、Collins and Quillian (1969)の結果については、誤反応(たとえば、カナリアは魚であるとか、カナリアは泳ぐといった文に正しいと反応してしまうようなもの)についての分析がきちんとなされておらず、明確な説明が書かれていない。その意味では、現在であれば、論文委員会によって採択されなかったような論文なのかもしれないのだ。
さらに、膨大なネットワークを構成していると考えられる記憶の構造について、そこから木構造に相当する部分だけがどうして抽出されて検索されるのかとか、「カナリアが呼吸をする」という文について、ダイレクトなリンクがはられていないということをどうやって確認できるのかとか、属性については特定のノードから大小さまざまな膨大な数のノードがリンクされていると考えられるはずだが、それらがどのようにして並列に処理されうるのかとか、また、たとえば「カナリアは呼吸をする」という文が提示されたとすると、どのようにして「カナリア」という語をLTMの中から見つけるのだろうか。コンピュータでいうハッシュ表のようなものがあって、「カナリア」という語のアドレスを一気にみつける、ということなのだろうか。
さらに、そうであったとして「呼吸」という述語についてはどうだろう。主語のアドレスを見つけて、そこから「呼吸」を見つけるように木構造を辿っていくと考えるよりは、「呼吸」という語についてもハッシングを行ってアドレスを見つけ、「カナリア」と「呼吸」の双方からお互いを辿っていく、と考えたほうが適切ではないだろうか。考えていくと不明な点が次々とでてくる。
このようなことを考えると、心理学や行動経済学などの実験・調査結果が引用されているのを目にした場合には、できるなら原典に遡って、どういう場合にどのような結果が得られたのか、その論証は適切であつたか、等をきちんと確認することが望ましいといえる。しかし、設計の現場で働いている人々には、そのような時間はないだろう。結果的に、解説書やテキストにかかれていることを信じるしかないのだが、そこには「仮説検証型の研究には一定のリスクがある」ということを考えておく態度が必要だ、といえる。ユーザビリティやUX、HCIに関連した心理学的法則や事実が掲載されている場合、それが仮説検証型の研究から得られたものであったなら、「そうも考えられるかな」くらいに態度を保留しておくのも一つの見識といえるだろう。
参考文献
Collins, A.M. and Quillian M.R. (1969) “Retrieval Time from Semantic Memory”, J. Verbal Learning and Verbal Behavior, 8, 240-247
記事で述べられている意見・見解は執筆者等のものであり、株式会社イードの公式な立場・方針を示すものではありません。